
We need QBCM to be available on as many Qbasic related websites as possible. That way ALL Qbasic coders can benefit from it. If you have a website dedicated to Qbasic then please become a host of QBCM too! All you have to do to become a host is join the QB Cult Ring, put up all the previous issues. You will recieve the new issues every month via e-mail, and your site will be listed on the QBCM host list!
Copyright (C) 2000 Christopher S. Charabaruk and Matthew R. Knight. All rights reserved. All articles, tutorials, etc. copyright (c) by the original authors. QB Cult Magazine is the exclusive property and copyright of Christopher Steffan Charabaruk and Matthew R. Knight.
Greetings, to the seventh issue of QB Cult Magazine. Although this issue isn't as big as the last one, it's still pretty packed, with a number of articles and reviews. We also (re)start a site of the month award, and introduce our new columns - Thoughts From the Darkness, by the famous DarkDread, and Demo Coders Corner, by Matthew R. Knight. There won't be Readme.txt any more (unless I start writing it, but my rants go here =). And starting next month, QbProgger's Power Coding column will begin.
I must welcome AlienQB as the magazine's new art... uhm... maker? Director? Yeah, our new art director. Right now, all he really does is create the award images, but there's more in store for him as we expand. Eventually, he might have others working under him!
You'll be seeing a lot from QbProgger in the coming months, as he doesn't just have a column, but starting in this issue, a series on creating physics-based engines. QbProgger has two articles this issue, including the first in his physics engine series. His RPG design series is the second, which ends this issue.
I don't really know what else to say, so go read something that makes more sense in this issue - in other words, anything other than this. Hehehe! Enjoy!
Chris Charabaruk (EvilBeaver), editor
Note: Regarding BASIC Techniques and Utilities, it was originally published by Ziff-Davis Press, producers of PC Magazine and other computer related publications. After ZD stopped printing it, they released the rights to Ethan Winer, the author. After communicating with Ethan by e-mail, he allowed me to reproduce his book, chapter by chapter, in QBCM. You can find a full text version of BASIC Techniques and Utilities at Ethan's website <www.ethanwiner.com>, or wait until the serialization is complete, when I will have an HTML version ready.
SCREEN 13 seems to be the most popular mode to use. Now, I know that SCREEN 12 uses 640 x 480 pixels, meaning higher resolution, but there are only 16 colors available. Is it possible to make more colors available with the same resolution? I know that libraries can help with higher resolutions and such, but how would I do it myself? What does it entail? Thanks, Gianfranco, GBGames
Graphics modes providing resolutions higher than 320x200 with 256 colors or more is known as SVGA (Super Video Graphics Adapter), and is not directly accessable with QB's graphics statements. It is possible to use SVGA in QB thanks to libraries (most notably Future Lib) or you can code your own routines. To do this you will need a knowledge of Assembly language. To learn how to code some SVGA routines you will need to obtain the Vesa specifications. They can easily be found on the internet.
Some time ago a tutorial series on SVGA in QB and Vesa was written for the now defunct QBasic: The Magazine. You can find QBTM at <http://qbtm.tekscode.com>
In the same magazine you will find a very easy to understand tutorial on Assembly language, written by Petter Holmberg.
I hope that helps.
- Matthew R. Knight
To place an ad, please e-mail <qbcm@tekscode.com>, subject QB Ads. Include your name (real or fake), e-mail address, and message. You may include HTML formatting (but risk the chance of the formatting being thrown out).
Qbasicnews.com has some jobs that need filling! If you are
interested in any of these please email webmaster@qbasicnews.com. These jobs
include:
Article Writers: We are looking for some talented writers who can write at least one quality review/article a week about a specific topic in programming. Whether it be music, graphics, coding techniques, how-to lessons, etc. You must be knowledgeable in any of those areas. Each person replying for this job must write an article before they are even accepted for this position. Some HTML experience is also required but may be negotiable! News Reporters: If you can wake up early in the morning and kick up a few news posts, we want you! In other words; we need early birds for this position. However, all news people will be considered. We need people who can find and post at least 4-5 news items each week! Personalities: If you are funny and told you should be a comedian and know how to program in qbasic, we want you! We are looking for writers who have that certain niche to make people laugh with words and who is very outgoing. You will need to be able to write one small articles/rants on qbasic a week for this job and keep it updated at all times. Currently none of these positions are paying jobs since Qbasic / Quickbasic News is still very new and is not making any money off sponsers yet. It's a fun filled exciting job with the chance to get closer to the industry you are so serious about, while also getting the online experience you need to possibly make it your full time career. All writers who are hired to do reviews, will receive games or hardware for that purpose. So, if you've been thinking about doing this for some time and were to scared to try, here's your shot! Send in your specifics and please allow up to 24 Hours for a reply back. |
By Ethan Winer <ethan@ethanwiner.com>
In Chapters 1 and 2 you learned how the BASIC compiler translates a source file into the equivalent assembly language statements, and how it allocates memory to store variables and constants. In particular, you saw that the BC compiler generates assembly language code directly for some statements, while for others it creates calls to routines in the BASIC libraries. Most of the code examples presented in that chapter dealt with simple variable assignments and calculations.
Of course, the compiler must do much more than merely assign and manipulate variables and other data. Equally important is controlling how your program operates, and determining which paths are to be taken as it progresses. In this chapter we will delve into the inner workings of control flow structures, with an eye toward writing programs that are as efficient as possible. As with the earlier chapters, this discussion includes numerous disassemblies of compiled BASIC code. Thus, you will see exactly what the compiler does, and how each control flow statement is handled.
This chapter also discusses the design of both static and non-static subprograms and functions, and compares the relative merits of each method. Many programmers do not fully understand the term Static, and find the related subject of recursive subroutines especially difficult to grasp.
BASIC supports four types of subroutines, and each will be described in this chapter: GOSUB routines, subprograms, DEF FN functions, and what I call "formal functions". YOu will notice that I use the terms subroutine and procedure interchangeably, to indicate a single block of code that may be executed more than once. You will also learn how parameters are passed to these procedures.
Finally, in this chapter I will discuss programming style. Programming in any language is arguably as much of an art as it is a science. But unlike, say, music, where a composer can write any sequence of notes and proclaim them acceptable, a computer program must at least work correctly. There are an infinite number of ways to accomplish any programming task, and I can make recommendations only. Which approach you choose will reflect both your own personal taste and style, as well as your current level of competence and understanding of programming in general.
All programs--regardless of the language in which they are written--require a mechanism for testing certain conditions and then performing different actions based on those conditions. Although there are many ways to perform tests and branches in a BASIC program, all of them do essentially the same thing. The BASIC control flow statements are GOTO, DO/LOOP, WHILE/WEND, IF/THEN/ELSE, FOR/NEXT, SELECT CASE, ON GOTO, and ON GOSUB. Because the capabilities of WHILE/WEND are also available with a DO/LOOP construct, the two will be discussed together.
In almost all cases, the BASIC compiler directly generates the code that controls a program's flow. One exception is when floating point values are used as a FOR counter, or as a WHILE or UNTIL condition. In those situations, calls are made to the floating point comparison routines in the BASIC runtime library. Another place is when you have a statement such as CASE ASC(X$), or IF LEFT$(X$, 10) = Y$. ASC and LEFT$ are also subroutines in the BASIC language library, and they too are invoked by calls.
It is important to reiterate that when dealing with integer test conditions, BC will in many cases create assembly language code that is as good as a human programmer would write. In the short program fragment that follows, all of the BASIC source code is shown translated to the equivalent assembly language statements. This listing was derived by compiling and linking the BASIC program for Microsoft CodeView, and then using CodeView to display the resultant code.
This is what you write:
DO X% = X% + 1 LOOP WHILE X% < 100
This is the result after compilation:
30: INC WORD PTR [X%] ;X% = X% + 1 CMP WORD PTR [X%],64 ;compare X% to 100 JL 30 ;jump if less to 30
Here the variable X% is incremented, and then compared to the value 100. (64 is the Hex equivalent to 100, which is how CodeView displays values.) If X% is indeed less than 100, the program jumps back to address 30 and continues processing the loop. Notice that while this example does not use a named label in the BASIC source code as the target for a GOTO, the equivalent assembly language code does. In this case, the label is the code at address 30. Do not confuse the addresses that assembly language must use as jump targets with the numbered labels that in BASIC are optional.
Modern programming philosophy dictates that GOTO and GOSUB statements should be avoided at all cost, in favor of DO and WHILE loops. However, all of these methods result in nearly identical code. Indeed, there is nothing inherently wrong with using GOTO when circumstances warrant it. By examining the program listing below, you will see that BASIC generates code that is identical for a GOTO as for a DO loop.
This is what you write:
Label: X% = X% + 1 IF X% < 100 THEN GOTO Label
This is the result after compilation:
30: INC WORD PTR [X%] ;X% = X% + 1 CMP WORD PTR [X%],64 ;compare X% to 100 JL 30 ;jump if less to 30
Since GOTO and DO/LOOP produce the same results, which one is better, and why? In general, a DO/LOOP is preferable for two reasons. First, it is a nuisance to have to create a new and unique label name for every location that a program may need to branch to. Admittedly, in a short program this will not be a problem. But in a large application with many small loops that test for keyboard input, you end up creating many labels with names such as GetKey1, GetKey2, and so forth. And if you inadvertently use the wrong label name, your program will not work correctly.
More important, however, is that for each label you define in a program, the BC compiler must remember its name and the equivalent address in the object code that the label identifies. Since label names can be as long as 40 characters and memory addresses require 2 bytes each to identify, a finite number of label names can be accommodated. By avoiding unnecessary labels, you are giving BC that much more memory to use for compiling your program.
There are several situations in which GOTO is preferable to a DO or WHILE loop. Indeed, one of my personal pet peeves is when a programmer tries to shoehorn structure into a program no matter what the cost. Consider the three different code fragments below; each waits for a key press and then assigns it to the variable Ky$.
This approach is the worst:
Ky$ = "" WHILE Ky$ = "" Ky$ = INKEY$ WEND
This method is better:
Label: Ky$ = INKEY$ IF Ky$ = "" GOTO Label
And this is better still:
DO Ky$ = INKEY$ LOOP WHILE Ky$ = ""
In the first example, an extra step is needed solely to clear Ky$ to a null string, so the initial WHILE will be true and execute at least once. Every string assignment adds 13 bytes to a program, and those 13 bytes can add up quickly in a large application.
The second example avoids the unnecessary assignment, but adds a label for GOTO to jump to. Although this label does require a small amount of additional memory while the program is being compiled, it does not increase the size of the final executable program file.
The last example is better still, because it avoids the need for a line label and also avoids an extra string assignment. Since a DO loop allows the test to be placed at either the top or bottom of the loop, you can force the loop to be executed at least once by putting the test at the bottom as shown here.
However, even this can be improved upon by eliminating the string comparison that checks if Ky$ is equal to a null string. If we replace LOOP WHILE Ky$ = "" with LOOP UNTIL LEN(Ky$), only 13 bytes of code are generated instead of 15. When two strings are compared (Ky$ and ""), each must be passed to the string comparison routine. Since LEN requires only one argument, the code to pass the second parameter is avoided.
There are some situations for which the GOTO is ideally suited. In the first two examples below, a complex expression is used as the condition for executing a DO WHILE loop, and the same expression is then used again within the loop.
DO WHILE (X% + Y%) * Z% > 13 IF (X% + Y%) * Z% = 100 THEN PRINT ... ... LOOP
DO WHILE ASC(MID$(S$, A%, B%)) > 13 IF ASC(MID$(S$, A%, B%)) > 100 THEN PRINT ... ... LOOP
Label:
Temp% = ASC(MID$(S$, A%, B%))
IF Temp% > 13 THEN
IF Temp% > 100 THEN PRINT
...
...
GOTO Label
END IF
In the first example, BASIC remembers the results of its test that checks if a (X% + Y%) * Z% is greater than 13, and it uses the result it just calculated in the next test that compares the same expression to 100. This is one more example of the kinds of optimizations BC performs as it compiles your programs. String expressions such as those used in the second example are of necessity more complex, and require calls to library routines. With this added complexity, BASIC unfortunately cannot retain the result of the earlier comparison, and it generates identical code a second time.
A more elegant solution in this case is therefore the GOTO as shown in the last example. Because the result of evaluating the expression is saved manually, it may be reused within the loop. As proof, the second DO WHILE example above requires 73 bytes to implement, as opposed to only 53 when Temp% and GOTO are used.
I should also point out that the most common and valuable use for GOTO is to get out of a deeply nested series of IF or other blocks of code. It is not uncommon to have a FOR/NEXT loop that contains a SELECT CASE block, and within that a series of IF/ELSE tests. The only way to jump out of all three levels at once is with a GOTO.
Unlike WHILE and DO loops that can test for nearly any condition and at either the top or bottom of the loop, a FOR/NEXT loop is intended to perform a block of statements a fixed number of times. A FOR/NEXT loop could also be replaced with code that compares a value and uses GOTO to reenter the loop if needed, but that is hardly necessary. My point is to yet again illustrate that all of BASIC's seemingly fancy constructs are no more than tests and GOTOs deep down at the assembly language level.
A FOR/NEXT loop determines the number of iterations that will be executed once ahead of time, before the loop begins. For example, the listing below shows a loop that changes the upper limit inside the loop. However the loop still executes 10 times.
Limit% = 10 FOR X% = 1 TO Limit% Limit% = 5 PRINT Limit% NEXT
The code that BASIC produces for the FOR/NEXT loop in the previous example is translated to the following equivalent during the compilation process.
Limit% = 10 Temp% = Limit% X% = 1 GOTO Next: For: Limit% = 5 PRINT Limit% X% = X% + 1 Next: IF X% <= Temp% THEN GOTO For
Please understand that changing a loop condition inside the loop is considered bad practice, because the program becomes difficult to understand. If you really need to alter the limit inside a loop, the loop should be recoded to use WHILE or DO instead. Another good reason for avoiding such code is because it is possible that future versions of BASIC will behave differently than the one you are using now. If Microsoft were to modify BASIC such that the limit condition were reevaluated at the NEXT statement, your code would no longer work. It is also considered bad practice to modify the loop counter variable itself (X% in the previous examples). However, this causes no real harm, and you should not be afraid to do that if the situation warrants it. Of course, changing the loop counter will affect the number of times the loop is executed.
BASIC provides two methods for testing conditions in a program, and executing different blocks of code based on the result. The most common method is the IF test, which can be used on a single variable, the result of an expression, the returned value from a function, or any combination of these. I won't belabor the most common uses for IF here, but I do want to point out some of its less obvious properties. Also, there are some situations where IF and ELSEIF are appropriate, and others where their counterpart, SELECT CASE, is better.
As you have already learned, a simple IF test will in most cases be translated into the equivalent assembler instructions directly. In some cases, however, the condition you specify is tested, while in others the *opposite* condition is tested. If you say IF X > 10 THEN GOTO Label, BASIC may change that to IF X <= 10 GOTO [next statement]. Which BASIC uses depends on what you will do if the condition is true, and how far away in the generated code the statements that will be executed are located. When a GOTO is to be performed if the test passes, then the relative position of the target label is also a factor.
A jump to a location either ahead in the code or more than 128 bytes backwards requires BASIC to generate more code. The 128 byte displacement is significant, because the 80x86 can perform a *conditional jump* to an address only a limited distance away. That is, after a comparison is made, the target address for a conditional jump such as "Jump if Greater" must be no more than that many bytes distant. However, an unconditional jump can be to any address within the same 64K code segment. (Bear with me for a moment, because the significance of this will soon become apparent.) This is shown in the next listing following.
IF X% = 100 THEN CMP Word Ptr [X%],64 ;compare X% to 100 JE 003A ;jump ahead if equal JMP Label ;else, skip ahead 003A: ;BASIC made this label Y% = 2 MOV Word Ptr [Y%],2 END IF Label: IF X > 8 GOTO Label CMP Word Ptr [X%],8 ;compare X% to 8 JG Label ;jump back if greater
In the first example above, BASIC compares the value of X% to 100 (64 Hex), and if equal jumps ahead to a label it created at address 003A Hex. Otherwise, a jump is made to the next statement in the program, which in this case is a named label. Although using two jumps may seem unnecessarily convoluted, it is necessary because BASIC has no way of knowing how many statements will follow at the time it compiles the IF test. Thus, it also cannot know whether the statement following the END IF will end up being 128 or more bytes ahead.
By jumping to another, unconditional jump, BC is assured that the generated code will be legal. (When BC finally encounters the END IF, it goes back to the code it created earlier, and completes the portion of the unconditional jump instruction that tells how far to go.) Some compilers avoid this situation and create the longer, two-jump code on a trial basis, but then go back and change it to the shorter form if possible. These are called two-pass compilers, because they process your source code in two phases. Unfortunately, current versions of Microsoft BASIC do not use more than one pass.
In the second example Label has already been encountered, and BC knows that the label is within 128 bytes. Therefore, it can translate the IF statement directly, without having to conditionally jump to yet another jump. Had the earlier label been farther away, though, an extra jump would have been needed. It is important to understand that forward jumps are always handled with more code than is likely necessary, because BASIC does not know how far ahead the jump must go. In fact, this same issue must be dealt with when writing in assembly language, since the conditional jump distance limitation is inherent in the 80x86 microprocessor.
The bottom line, therefore, is that you can in many cases reduce the size of your programs by controlling in which direction a conditional jump will be performed. For example, almost all programs must at some point sit in a loop waiting until a key is pressed. The next listing shows two common ways to do this, with one testing for a key press at the top of the loop, and the other doing the test at the bottom.
DO UNTIL LEN(INKEY$) ;this comprises 18 bytes 0030: CALL B$INKY ;call INKEY$ PUSH AX ;pass the result to LEN CALL B$FLEN ;AX now holds the length AND AX,AX ;see if it's zero JZ 0042 ;yes, jump to LOOP JMP 0044 ;no, jump out of loop 0042: LOOP JMP 0030 ;jump back to DO 0044: DO ;this is only 15 bytes LOOP UNTIL LEN(INKEY$) CALL B$INKY ;call INKEY$ PUSH AX ;as above CALL B$FLEN AND AX,AX JZ 0044 ;jump back if zero
Viewed from a purely BASIC perspective, these two examples operate identically. But as you can see, the code that BASIC creates is more efficient for the second example. When BASIC encounters the first DO statement, it has no idea how many more statements there will be until the terminating LOOP. Therefore, it has no recourse but to create an extra jump. In the second example, the location of the DO is already known to be within 128 bytes, so the LOOP test can branch back using the shorter and more direct method.
An ELSEIF statement block is handled in a similar fashion, with code that directly compares each condition and branches accordingly. Because the code to be executed if the IF is true is always after the IF test itself, the less efficient two-jump code must be generated. A simple IF/ELSEIF follows, shown as a mix of BASIC and assembly language statements.
IF X% > 9 THEN CMP Word Ptr [X%],9 ;compare X% to 9 JG 003A ;assign Y% if greater JMP 0043 ;else jump to next test 003A: Y% = 1 MOV Word Ptr [Y%],1 ;assign Y% JMP 0066 ;jump out of the block ELSEIF X% > 5 THEN 0043: CMP Word Ptr [X%],5 ;as above JG 004D JMP 0066 004D: Y% = 2 MOV Word Ptr [Y%],2 END IF 0066: ... ...
Aside from the additional jumping over jumps that are added to all forward address references, this code is translated quite efficiently. In this situation, the compiled output is identical to that produced had SELECT CASE been used. However, there is one important situation in which SELECT CASE is more efficient than IF and ELSEIF.
For each ELSEIF test condition, code is generated to create a separate comparison. When a simple comparison such as X% > 9 is being made, only one assembly language statement is needed. But when an expression is tested--for example, ABS((X% + Y%) * Z%)) > 9--identical code is generated repeatedly. This is illustrated in the listing that follows.
IF ABS((X% + Y%) * Z%) = 5 THEN A% = 1 ELSEIF ABS((X% + Y%) * Z%) = 6 THEN A% = 2 ELSEIF ABS((X% + Y%) * Z%) = 7 THEN A% = 3 END IF
Each time BC encounters the expression ABS((X% + Y%) * Z%), it duplicates the same assembly language statements. But when SELECT CASE is used, the expression is evaluated once, and used for each subsequent test. The first example in the next listing shows how SELECT CASE could be used to provide the same functionality as the preceding IF/ELSEIF block, but with much less code. The second example then shows what SELECT CASE really does, using an IF/ELSEIF equivalent.
You write it this way:
SELECT CASE ABS((X% + Y%) * Z%) CASE 5: A% = 1 CASE 6: A% = 2 CASE 7: A% = 3 CASE ELSE END SELECT
BASIC really does this:
Temp% = ABS((X% + Y%) * Z%) IF Temp% = 5 THEN A% = 1 ELSEIF Temp% = 6 THEN A% = 2 ELSEIF Temp% = 7 A% = 3 END IF
As you can see, SELECT CASE evaluates the expression once, stores the result in a temporary variable, and then uses that variable repeatedly for all subsequent comparisons. Therefore, when the same expression is to be tested multiple times, SELECT CASE will be more efficient than IF and ELSEIF. This is also true for string expressions and other functions. For example, SELECT CASE LEFT$(Work$, 10) will result in less code and faster performance than using IF and ELSEIF with that same expression more than once.
Another important feature of SELECT CASE is its ability to use either variable or constant test conditions, and to operate on a range of values. For example, the C language Switch statement which is the equivalent of BASIC's SELECT CASE can use only constant numbers for each test. BASIC is particularly powerful in this regard, and allows any legal expression for each CASE condition. For example, CASE IS > (Y AND Z) is valid, and so is CASE 0 TO Max. CASE also accepts multiple conditions separated by commas such as CASE 1, 3, 4 TO 100, -10 TO -1. In this case, the statements that follow will be executed if the selected expression equals 1, 3, any value between 4 and 100 inclusive, or any value between -10 and -1 inclusive.
It is also worth mentioning here that QuickBASIC version 4.0 contains an interesting and irritating quirk that requires a CASE ELSE in the event that none of the tests match. Had the CASE ELSE been omitted from the previous example and the value of the expression was not between 5 and 7, QuickBASIC 4.0 would issue a "CASE ELSE expected" error at run time. Fortunately, this has been repaired in QuickBASIC 4.5 and later versions.
Notice that this is not a bug in QuickBASIC. Rather, it is the behavior described in the ANSI (American National Standards Institute) specification for BASIC. At the time QuickBASIC 4.0 was introduced, Microsoft mistakenly believed the then-proposed ANSI standard for BASIC would be significant. As that standard approached fruition, it became clear to Microsoft that the only standard most programmers really cared about was Microsoft's.
One final point I cannot make often enough is the inherent efficiency of integer operations and comparisons. This is especially true in the comparisons that are made in both IF and CASE tests. In the first example below, each of the characters in a string is tested in turn. The second example shows a much better way to write such a test, by obtaining the ASCII value once and using that for subsequent integer comparisons.
Not recommended:
FOR X = 1 TO LEN(Work$)
SELECT CASE MID$(Work$, X, 1)
CASE CHR$(9): PRINT "Tab key"
CASE CHR$(13): PRINT "Enter key"
CASE CHR$(27): PRINT "Escape key"
CASE "A" TO "Z", "a" TO "z": PRINT "Letter"
CASE "0" TO "9": PRINT "Number"
END SELECT
NEXT
Much more efficient:
FOR X = 1 TO LEN(Work$)
SELECT CASE ASC(MID$(Work$, X, 1))
CASE 9: PRINT "Tab key"
CASE 13: PRINT "Enter key"
CASE 27: PRINT "Escape key"
CASE 65 TO 90, 97 TO 122: PRINT "Letter"
CASE 48 TO 57: PRINT "Number"
END SELECT
NEXT
In the first program the SELECT itself generates 27 bytes, which is comprised of a call to the MID$ function and then a call to the string assign routine. A string assignment is needed to save the MID$ result in a temporary variable for the subsequent tests that follow. Each CASE test that uses CHR$ adds 27 bytes, and this includes the call to CHR$ as well as an additional call to the string comparison routine. Testing for the letters adds 75 bytes, and testing for the numbers adds 39 more. This results in a total code size of 222 bytes, not counting the FOR/NEXT loop.
Contrast that with only 131 bytes for the second example, in which the SELECT portion requires only 26 bytes. Although an extra call is needed to obtain the ASCII value of the extracted character, the lack of a subsequent string assignment more than makes up for that. Further, the tests for 9, 13, and 27 require only 13 bytes each, compared to 27 when CHR$ values were used. The letters test requires 43 bytes, and the numbers test only 23.
Clearly this is a significant improvement, especially in light of the small number of tests that are being performed here. In a real program that performs hundreds of string comparisons, replacing those with integer comparisons where appropriate will yield a substantial size reduction.
When you use AND or OR in an IF test, what is really being compared is either 0 or -1. That is, BASIC evaluates the *truth* of each expression being tested on both sides of the AND or OR, and a truth in BASIC always results in one or the other of these values. Once each expression has been evaluated, the results are combined using an assembly language AND or OR instruction, and a branch is then made accordingly. Remember that when integers are treated as unsigned, setting all of the bits to 1 results in a value of -1.
In chapter 2 I showed how the various logical operators are used to manipulate bits in an integer or long integer variable. The concept is identical when these operators are used for decision-making in a BASIC program. The difference is really more a matter of semantics than definition. That is, the same bit manipulation is performed, only in this case on the result of the truth of a BASIC expression. This is shown in context below, where two test expressions are combined using AND.
IF X > 1 AND Y < 2 THEN CMP Word Ptr [X%],1 ;compare X% to 1 MOV AX,0 ;assume False JLE 003B ;we assumed correctly DEC AX ;wrong, decrement to -1 003B: CMP Word Ptr [Y%],2 ;now compare Y% to 2 MOV CX,0000 ;assume False JGE 0046 ;we assumed correctly DEC CX ;wrong, decrement to -1 0046: AND CX,AX ;combine the results AND CX,CX ;(this is redundant) JNZ 004F ;if not 0 assign Z% JMP 0055 ;else jump past END IF Z = 3 004F: MOV Word Ptr [Z%],3 ;assign Z% END IF 0055: ... ...
The result of the first comparison is saved in the AX register as either 0 or -1, and the second is saved in CX using similar code. Once both tests have been performed and AX and CX are holding the appropriate values, the registers are then tested against each other using AND. The instruction AND CX,AX not only combines the results, but it also sets the CPU's Zero Flag to indicate if the result was zero or not. Therefore, the second test that uses AND to compare CX against itself to check for a zero result is redundant. At only 2 additional bytes, the impact on a program's size is not terribly significant. However, this shows first-hand the difference between code written by a compiler and code written by a person.
OR conditions are handled similarly, except the assembly language OR instruction is used instead of AND. When multiple conditions are being tested using combinations of AND and OR and perhaps nested parentheses as well, additional similar code is employed.
There are many situations where all that is really necessary is to test for a zero or non-zero condition. For example, it is common to use an integer variable as a True/False "flag" which can be set in one part of a program, and tested in another. By understanding the underlying code that BASIC creates, you can help BASIC to reduce the size of your programs enormously. In particular, avoiding a comparison with an explicit value lets BASIC generate fewer comparison instructions. The listing below shows how you can test multiple flags using AND, but with much less resulting code than using an explicit comparison.
IF Flag1% AND Flag2% THEN MOV AX,[Flag2%] ;move Flag2% into AX AND AX,[Flag1%] ;AND that with Flag1% AND AX,AX ;(this is redundant) JNZ 0063 ;if not zero assign Z% JMP 0069 ;else skip past END IF Z% = 3 0063: MOV Word Ptr [Z%],3 END IF 0069: ... ...
The key here is that zero is always used to represent False, and -1 to represent a True condition. That is, instead of writing IF Flag1% = -1 AND Flag2% = -1, using IF Flag1% AND Flag2% provides the same results. At only 20 bytes of generated code, this method is far superior to tests for an explicit -1 which require 37 bytes. If you recall, in Chapter 2 I showed how the various bits in a variable can be turned on or off with AND. Thus, 1111 AND 1111 equals 1111, while 1111 AND 0000 equals 0.
Notice that using 0 and -1 has many other benefits as well. For example, the NOT operator which was also described in Chapter 2 can toggle a variable between those values. If all of the bits in a variable are presently zero, then NOT Variable% results in all ones (-1). This property can also be used to enhance a program's readability, by using NOT much like you would in an English sentence. For example, the code following the line IF NOT Flag% THEN will be executed if Flag% is 0 (False), but it will not be executed if Flag% is -1 (True).
In fact, an explicit comparison is optional if you need to test only for a non-zero value. IF Variable <> 0 THEN can be reduced to IF Variable THEN, and the statements that follow will be executed as long as Variable is not 0. Notice that the only saving here is in the BASIC source, since either comparison creates ten bytes of assembler code. But when using long integers, the short form saves five bytes--14 bytes versus 19 for an explicit comparison to zero.
NOT is equally valuable when toggling a flag variable between two values. If you have, say, an input routine that keeps track of the Insert key status, then you could use Insert% = NOT Insert% each time you detect that the Insert key was pressed. The first time the operator presses that Key, the Insert flag will be switched from the default start-up value of 0 to -1. Then using Insert% = NOT Insert% a second time will revert the bits back to all zeros. In fact, it is a common technique to define True and False variables (or constants) in a program using this:
False% = 0 True% = NOT False%
Most programmers understand how to use parentheses to force a particular order of evaluation. By default, BASIC performs multiplication and division before it does addition and substraction. When operators of the same precedence are being used, then BASIC simply works from left to right. However, the order in which logical comparisons are made is not always obvious. This can become particularly tricky if you are using some of the shorthand methods I described earlier.
For example, consider the statements IF X AND Y > 12, IF NOT X OR Y, and IF X AND Y OR Z. In the first example, the truth of the expression Y > 12 is evaluated first, with a result of either 0 or -1. Then, that result is combined logically with the value of X using AND. The resulting order of evaluation is performed as if you had used IF X AND (Y > 12). The other expressions are evaluated as IF (NOT X) OR Y and IF (X AND Y) OR Z.
The last logical operators we will consider are EQV and XOR. These are used rarely by most BASIC programmers, probably because they are not well understood. However, EQV can dramatically reduce the size of a program in certain circumstances. It is not uncommon to test if two conditions are the same, whether True or False. EQV stands for Equivalent, meaning it tests if the expressions are the same--either both true or both false. All three program fragments below serve the same purpose, however the first generates 57 bytes, while the second and third create only 16 bytes.
IF (X = -1 AND Y = -1) OR (X = 0 AND Y = 0) THEN ... END IF IF X EQV Y THEN ... END IF IF NOT (X XOR Y) THEN ... END IF
Although these examples could be replaced with a simple comparison that tests if X equals Y, EQV can reduce other, more elaborate AND and OR tests. For example, you could replace this:
IF (X = 10 AND Y = 100) OR (X <> 10 AND Y <> 100)
with this:
IF X = 10 EQV Y = 100
and gain a handsome reduction in code size. Notice that because of the way EQV works, the third example in the listing above results in identical assembly language code as the second. XOR is true only when the two conditions are different, thus NOT XOR is true when they are the same.
One final point worth mentioning is that you can assign a variable based on the truth of one or more expressions. As you saw earlier, every IF test that is used in a BASIC program adds a minimum of 3 extra bytes for a second, unconditional jump. That additional code can be avoided in many cases by assigning a variable based on whether a particular condition is true or not. In the code examples that follow, both program fragments do the same thing, except the first requires 25 bytes compared to only 14 for the second.
IF Variable = 20 THEN Flag = -1 ELSE Flag = 0 END IF Flag = (Variable = 20)
In either case, the truth of the expression Variable = 20 must be evaluated. However, the IF method adds code to jump around to different addresses that assign either -1 or 0 to Flag. The second example simply assigns Flag directly from the 0 or -1 result of the truth test. Other variants on this type of programming are statements such as A = (B = C), and Flag = (LEN(Temp$) <> 0 AND Variable < 50). Note that the surrounding parentheses are shown here for clarity only, and BASIC produces the same results without them.
There is one important point regarding AND testing you should be aware of. Although the code that BASIC creates to implement these logical tests is very efficient, in some cases a different approach can yield even better results. When many conditions are tested, QuickBASIC creates assembly language code to evaluate all of them before making a decision. This can be wasteful, because often one of the conditions will be false, negating a need to test the remaining conditions. For example, this statement:
IF Any$ = "Quit" AND IntVar% > 100 AND Float! <> 0 THEN PRINT "True"
requires that all three conditions be tested before the program can proceed. But if Any$ is not equal to "Quit", there is no need reason to spend time evaluating the other tests.
The solution is to instead use nested IF tests, preferably placing the most likely (or simplest) tests first, as shown below.
IF Any$ = "Quit" THEN
IF IntVar% > 100 THEN
IF Float! <> 0 THEN
PRINT "True"
END IF
END IF
END IF
Here, if the first test fails, no additional time is wasted testing the remaining conditions. Further, using the nested IF tests with QuickBASIC also results in less code: 50 bytes versus 64. Note, however, that BASIC PDS [and VB/DOS] incorporate a technique known as *short circuit expression evaluation*, which generates slightly more efficient code when AND is used. With the newer compilers, each condition is tested in sequence, and the first one that fails causes the program to skip over the code that prints "True". But even with this improved code generation, you should still place the most likely tests first.
The last non-procedural control flow statements I will discuss here--ON GOTO and ON GOSUB--are used infrequently by many BASIC programmers. But when you need to test many different values *and* those values are sequential, ON GOTO and ON GOSUB can reduce substantially the amount of code that BASIC generates. For clarity, I will use ON GOTO for most of the examples that follow. Both work in a similar fashion except with ON GOSUB, execution resumes at the next BASIC statement when the subroutine returns.
You have already seen that IF/ELSEIF and SELECT CASE blocks are not as efficient as they could be, because the compiler does not know how far ahead the END IF or END SELECT statements are located. Therefore, no matter how trivial the IF or CASE tests being performed are, a pair of jumps is always created even when a single jump would be sufficient. Further, when many tests are necessary, there is no avoiding at least some amount of code for each comparison. This is where ON GOTO can help.
Rather than perform a series of separate tests for each value being compared, ON GOTO uses a lookup table which is imbedded in the code segment. This table is merely a list of addresses to branch to, based on the value of the variable or expression being evaluated. If the value being tested is 1, then a branch is taken to the first label in the list. If it is 2, the code at the second label is executed, and so forth.
As many as 60 labels can be listed in an ON GOTO statement, although the number being tested can range from 0 to 255. If the value is 0 or higher than the number of items in the list, the ON GOTO command is ignored, and execution resumes with the statement following the ON GOTO. Negative values or values higher than 255 cause an "Illegal function call" error. A simple example showing the basic syntax for ON GOTO is shown below.
INPUT "Enter a value between 1 and 3: ", X ON X GOTO Label1, Label2, Label3 PRINT "Illegal entry!" END Label1: PRINT "You pressed 1" END Label2: PRINT "You pressed 2" END Label3: PRINT "You pressed 3" END
Notice that the more labels there are, the bigger the savings in code size. ON GOTO adds a fixed overhead of 70 bytes, 61 of which is the size of the library routine that evaluates the value and actually jumps to the code at the appropriate label. The remaining 9 bytes are needed to load the value being tested and pass that on to the ON GOTO routine. However, for each label in the list, only 2 bytes are required in the lookup table to hold the address.
Compare that to SELECT CASE which requires 6 bytes of set-up code (when an integer is being tested), and 13 bytes more to process each CASE. Thus, the crossover point at which ON GOTO is more efficient is when there are 6 or more comparisons. Notice that if ON GOTO is used in more than one place in a program, the savings are even greater because the 61-byte library routine is added only once.
Again, ON GOTO has the important restriction that all of the values must be sequential. However, this limitation can also be turned into a feature by taking advantage of the inherent efficiency of lookup tables.
Using a lookup table is a very powerful technique, because you can determine a result using an index rather than actually calculating the answer. A lookup table is commonly used to determine log and factorial functions, since those calculations are particularly tedious and time consuming. With a lookup table you would calculate all of the values once ahead of time, and fill an array with the answers. Then, to determine the factorial for, say, the number 14, you would simply read the answer from the fourteenth element in the array.
You can apply this same technique in BASIC using a combination of INSTR and ON GOTO or ON GOSUB. Although INSTR is intended to find the position of one string within another, it is also ideal for looking up characters in a table. Imagine you have written an input routine that must handle a number of different keys, and branch according to which one was pressed. One way would be to use an IF/ELSEIF or SELECT CASE block, with one section devoted to each possible key. But as you saw earlier, once there are more than 5 keys to be recognized, either of those constructs are less efficient than ON GOTO.
The approach I often use is to combine INSTR and ON GOSUB to branch according to which function key was pressed. The beauty of this method is that a value of zero (or one that is out of range) causes control to fall through to the next statement. Therefore any keys that are not explicitly being tested for are simply ignored. This is shown in context below.
DO
DO 'wait for a key press
K$ = INKEY$
Length% = LEN(K$)
LOOP UNTIL Length%
IF Length% = 2 THEN 'it's an extended key
Code$ = RIGHT$(K$, 1) 'isolate the key code and branch accordingly
ON INSTR(";<=>?@ABCD", Code$) GOSUB ...
END IF
LOOP UNTIL K$ = CHR$(27) 'until they press Esc
Here, extended keys are identified by a length of 2, and the key code is then isolated with RIGHT$. The punctuation and letters within the quotes are characters 59 through 68, which correspond to the extended codes for F1 through F10. (A list of all the extended key codes is in your BASIC owner's manual.) Of course, any arbitrary list of key codes could be used. Further, the key codes do not need to be contiguous. For example, to branch on the Up arrow, Down arrow, Ins, Del, PgUp, and PgDn keys you would use "HPRSIQ" as the source string. Any other mix of characters could also be used, including Alt keys.
Another interesting and clever trick that combines INSTR and ON GOTO lets you test multiple keys regardless of capitalization. The short program below accepts a character, and uses INSTR to look it up in a table of upper and lower case character pairs.
PRINT "Yes/No/Load/Save/Retry/Quit? ";
DO
K$ = INKEY$
LOOP UNTIL LEN(K$) = 1
ON (INSTR("YyNnLlSsRrQq", K$) + 1) \ 2 GOTO ...
After adding 1 and dividing that by 2, the result will indicate in which character pair the choice was found. This technique could also be extended to include 3- or 4-character groups, or any other combination of characters. Since any value between 0 and 255 is legal for an ASCII character, INSTR can be used in other, more general lookup situations as well.
There are four primary subroutine types that BASIC supports: GOSUB subroutines, DEF FN functions, called subprograms, and what I refer to as "formal functions". Each has its own advantages and disadvantages, which I will describe momentarily. But I would first like to introduce several terms that will be used throughout the discussion that follows.
The first is *module*, which is a series of BASIC program statements kept in their own separate source file. All modules have a main portion, and some also have procedures within a SUB or FUNCTION block. The main portion of a program is that which receives control when the program is first run. When a program is comprised of multiple modules, each additional module has a main portion, although code within that portion is rarely executed. In fact, there are only two ways to access code in the main portion of an ancillary module: One is to create a line label and use that as the target for ON ERROR or another "ON" event. The other is to define a DEF FN function and invoke the function.
The second term is *variable scope*, which indicates where in a program a variable may be accessed. Variables that are used in the main portion of a program are accessible anywhere else in the main, but not within a SUB or FUNCTION block. Likewise, a variable that is defined within a SUB or FUNCTION is by default private to that procedure. The overwhelming advantage of private variables is that you do not have to worry about errors caused by inadvertently using the same variable name twice.
The third term is *SHARED*, and it overrides the default private scope of a variable used in a procedure. SHARED may be used in either of two ways. If it is specified with a DIM statement in the main body of a program--that is, DIM SHARED Variable--the variable is established as being shared throughout the entire source file. Even though DIM is usually associated with arrays, it can be used this way to extend a variable's scope.
SHARED may also be used within a subroutine to share one or more variables with the main portion. Notice that the statement SHARED Variable inside a procedure defines the variable as being shared with the main portion of the program only. SHARED used within a procedure does not share the named variable with any other procedures. The only exception is when other procedures also use SHARED with the same variable name. In that case they are shared between procedures, as well as with the main program.
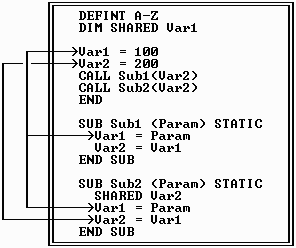
The fourth term is *COMMON*, which is related to SHARED in that it also lets you share variables among procedures. However, COMMON has the additional property of allowing variables to be shared by procedures that are not in the same physical source file. When BC compiles your program, it translates your variable names to memory addresses. Thus, those names are not available when the program is linked to other object files. Variables that are listed in a COMMON statement are placed in a separate portion of the data segment which is reserved just for that purpose. Therefore, other program modules using COMMON can also access those variables in that portion of DGROUP.

COMMON can also be combined with SHARED, to specify that one or more variables be shared throughout the main program as well as with other modules. That is, the statement COMMON SHARED Variable tells BASIC that Variable is to be both DIM SHARED and COMMON. To establish a TYPE variable as COMMON, you must state the type name as well: COMMON TypeVar AS MyType. In all cases, COMMON statements must precede the executable statements in a program. The only statements that may appear before COMMON are other non-executable statements such as DECLARE, CONST, and '$STATIC.
Because the variable names listed in a COMMON statement are not stored in the final program, the names used in one module do not need to be the same as the corresponding names in another module. You could, for example, have COMMON X%, Y$, Z# in one file, and COMMON A%, B$, C# in another. Here, X% refers to the same memory location as A%; Y$ is the same variable as B$, and so forth. It is imperative, however, that the order and type of variables match. If one file has an integer followed by a string followed by a double precision variable, then all other files containing a COMMON statement must have their COMMON variables in that same order. This is one good reason for storing all COMMON statements in a single include file, which is included by each module that needs access to the COMMON variables.
One or more arrays may also be listed as COMMON; however, the rules are different for static and dynamic arrays. When a dynamic array is to made COMMON, it should be dimensioned in the main program only, following the COMMON statement. (But you may use REDIM in another module if necessary, to change the array's size.) Static arrays must be dimensioned in each module, before the associated COMMON declaration. Of course, all array types must match across modules--you may not list a static array as the first COMMON item in one file, and then list a dynamic array in that same position in another file.
There are actually two forms of COMMON statement: the blank COMMON and the named COMMON. The examples shown thus far are blank COMMON statements. A named COMMON block lets you specify selected variable groups as COMMON, to avoid having to list many variables when all of them are not needed in a given module. A COMMON block is named by preceding the variable list with a name surrounded by slash characters. For instance, this line:
COMMON /IntVars/ X%, Y%, Z%
establishes a named COMMON black called IntVars. By creating several such named blocks you may share only those that are actually needed in a given module.
In this case, the block name is stored in the object file, and LINK ensures that the COMMON variables in each module share the same addresses. One important limitation of a named COMMON block is that it cannot be used to pass information between programs that use CHAIN.
The fifth term is *STATIC*, which I described in a slightly different context in the section about data in Chapter 2. When you add the STATIC option to a SUB or FUNCTION definition, BASIC treats the variables within that procedure very differently than when STATIC is omitted. With STATIC, memory in DGROUP is allocated by the compiler for each variable, and that memory is permanently reserved for use by those variables.
When STATIC is not specified, the variables in the routine are by default placed onto the system stack. This means that sufficient stack memory must be available, although that memory can then be used again later for variables in other procedures. An important side effect of using the stack for variable storage is that the memory is cleared each time the subprogram or function is entered. Therefore, all numeric variables are initialized to zero, and strings are initialized to null. Any arrays within a non-static procedure are by default dynamic, which means they are created upon entry to the routine and erased when the routine exits.
STATIC also has an additional meaning in subprograms and functions; it can establish variables as being private to a procedure. If a variable has been declared as shared throughout a module by using DIM SHARED in the main portion of the program, using the statement STATIC Variable inside the subroutine will override that property. Thus, Variable will be local to the procedure, and will not conflict with a global shared variable of the same name. STATIC within a subprogram or function also lets you use the same name for a variable that was already given to a named constant.
Many programmers find the use of the term STATIC for two very different purposes confusing, and rightly so. It would have made more sense to use a different keyword, perhaps LOCAL, to limit a variable's scope. And to further confuse the issue, the '$STATIC metacommand is used to establish the memory storage method for arrays. None the less, STATIC always indicates that memory for a variable is permanently allocated, and it may also specify that a variable is private to a procedure.
The final term I want to introduce now is *recursion*. The classic definition of a recursive procedure is that it may call itself. While this is certainly true, that doesn't really explain what recursion is all about, or how it could be useful. I will cover recursion in depth momentarily, but for now suffice it to say that recursion is often helpful when manipulating tree-structured information.
For example, a program that lists all of the files on a hard disk would most likely be based on a recursive subroutine. Such a program would first change to the root directory, and then call the routine to read and display all of the file names it finds there. Then for each directory under the current one, the routine would change to that directory and call itself again to read and display the files in that directory. And if more directories were found at the next level down, the routine would call itself yet again to process all of those files too. This continues until all of the files in all directories on the hard disk have been processed.
Another application for recursion is a subroutine that sorts an array on more than one key. For example, consider a TYPE array in which each element has components for a first name, a last name, and address fields. You might want to be able to sort that array first by last name, then by first name, and then by zip code. That is, all of the Smiths would be grouped together, and within that group Adam would be listed before John. All of the John Smiths would in turn be sorted in zip code order.
By employing recursion, the routine would first sort the entire array based on the last name only. Next, it would identify each range of elements that contain identical last names. The routine would then call itself to sort that subgroup, and call itself again to sort the subgroup within that group based on zip code.
There is a fundamental difference between subroutines and functions. A subroutine is accessed with either a CALL or GOSUB statement, and a function is invoked by referencing its name. In general, a subroutine is used to perform an action such as opening a group of files, or perhaps updating a screen-full of information. A function, on the other hand, returns a value such as the result of a calculation. A string function also returns information, although in this case that information is a string.
Notice that the type of information returned by a function is independent of the type of parameters, if any, that are passed to it. For example, BASIC's native STR$ function accepts a numeric argument but returns a string. Likewise, a numeric function such as INSTR accepts two strings and returns a single integer. This is also true for functions that you design using either DEF FN or FUNCTION.
Although a function is primarily used for calculations and a subroutine for performing one or more actions, there is no hard and fast distinction between the two. You could easily design a subroutine that multiplies three numbers and returns the answer in one of the parameters. Similarly, a function could be written to clear the screen and then open a file. Which you use and when will depend on your own programming style. However, there are definite advantages to using functions where appropriate.
One immediately obvious benefit of a function is that a value can be returned without requiring an additional passed parameter. Each variable that is passed as a parameter requires 4 bytes of code for setup, plus an additional 5 bytes within the subroutine each time it is accessed.
Another important advantage of using a function is BASIC's automatic type conversion. If you assign a single precision variable from the result of an integer function, BASIC will convert the data from one format to the other transparently. In fact, a simple assignment from a variable of one type to that of another type is also handled for you by the compiler. But if a routine is written to pass the value back as a parameter, then you must use whatever type of data the subprogram expects.
Although most high-level languages require the programmer to match explicitly the types of data being assigned, Microsoft BASIC has done this automatically since its inception. When you write Var1! = Var2%, BASIC treats that as Var1! = CSNG(Var2%). Object oriented programming languages use the term *polymorphism* to describe such automatic type conversion.
The primary advantage a GOSUB routine holds over all of the other subroutine types is that it can be accessed very quickly. Translated to assembly language a GOSUB statement is but three bytes in length, and its speed is surpassed only by a GOTO. When the only thing that matters is how fast a subroutine can be called, GOSUB has the clear advantage. However, there are many limitations inherent in a GOSUB.
The most important restriction is that arguments cannot be passed using GOSUB. Therefore, any variables must be assigned before invoking the routine, and possibly reassigned when it returns. For example, if a subroutine requires two parameters--perhaps a row and column at which to print a message--those variables must be assigned before the GOSUB can be used. And if a value is being returned, your program must know the name of the variable that was assigned within the GOSUB routine.
Another important limitation is that the target line label must be in the same block of code as the GOSUB. Although a GOSUB is legal within a SUB or FUNCTION, both the GOSUB and the routine it calls must be located in the same procedure. Likewise, a GOSUB in the main body of a program cannot access a subroutine inside a procedure, or vice versa. [And of course you cannot invoke a GOSUB routine that is located in a different source module.]
Both of these problems restrict your ability to reuse a subroutine in more than one program. One of the goals of modern structured programming is the ability to design a routine for one application, and also use it again later in other programs. The only way to do that using GOSUB routines is to establish a variable naming convention, and always use variables and line labels with those unique names.
Subprograms were introduced with QuickBASIC version 2.0, and they improve greatly on GOSUB routines in many respects. The most important advantages of a subprogram are that it accepts passed parameters, and that variables used within the subprogram are local by default. Besides the obvious benefit of not having to worry about variable naming conflicts, these properties allow you to create your own toolbox of useful subroutines, and use them repeatedly in different programming projects. I will discuss this use of subprograms in detail later in this chapter.
A subprogram is accessed using the CALL statement, and any number of arguments may optionally be passed to the routine. A subprogram is defined with a statement of the form SUB SubName (Param1, Param2, ...) STATIC. The parameters and surrounding parentheses are optional, as is the STATIC directive. Of course, the number of arguments passed to a subprogram must match the number of parameters it expects.
As you can see, subprograms have many advantages over GOSUB routines. However, they are not a magical panacea for every programming problem. Each subprogram includes a fixed amount of overhead just to enter and exit it. Because of the complexities of accessing incoming parameters, a *stack frame* must be created by the compiler upon entry. A stack frame is simply a fancy name for an area of memory that holds the addresses of the incoming parameter. However, this requirement adds a fair amount of code to each subprogram.
Eight bytes of code are needed to set up and call the internal BASIC routine that creates the stack frame, and the routine itself comprises another 35 bytes. Eight more bytes are needed to call the routine that exits a subprogram, and that routine adds contains 26 bytes. Finally, all but the last subprogram in a source file needs a 3-byte jump to skip over the other subprograms that follow. Therefore, a total of 80 bytes are added to any program that uses a subprogram rather than a GOSUB routine. It is important to point out, however, that the 61 bytes used by the library routines to enter and exit a subprogram are added to the final .EXE file only once.
It is also worth mentioning that BASIC PDS provides the /Ot switch, which eliminates the usual overhead incurred from calling the routines needed to enter and exit a subprogram. Although using /Ot avoids the code that is otherwise added, there is one important restriction: You may not use a GOSUB within the subprogram. When a program performs a GOSUB, the address to return to is placed onto the stack, for retrieval later when the subroutine returns. Likewise, when a subprogram is called, both a segment and address to return to are put on the stack.
If a GOSUB were used inside the subprogram and an EXIT SUB was then encountered within the GOSUBed subroutine, the return addresses on the stack would be out of order. Thus, the subprogram would return to the wrong place, with undoubtedly disastrous consequences. To avoid this, BASIC by default saves the address to return to when the subprogram is first entered, and uses that when it is exited. Therefore, when the compiler sees that a GOSUB is being used, it does not use the abbreviated method even if /Ot has been specified.
Although using /Ot makes a subprogram (and function) much faster by eliminating the overhead to call the entry and exit routines, there is no actual savings in code size. A series of assembler NOP (No Operation) instructions are placed where the entry and exit code would have been. However, those empty instructions are never executed. We can only hope that in future releases of BASIC PDS Microsoft will improve BC's code generation to eliminate these unnecessary instructions. [Yeah, right.]
Another problem with subprograms is that programmers tend to use them to excess. For example, I have seen people create subprograms to increment and decrement integer variables even though it is far more efficient to do that with in-line code. The statement X% = X% + 1 creates only 4 bytes of code, compared to 9 for a single call to a subprogram to do the same thing! However, incrementing long integer or floating point variables does take more code than invoking a subprogram with a single parameter, so a subprogram could be useful in that case. Only by counting the number of times a subprogram will be used and comparing that to the overhead incurred can you determine whether there will be any savings.
Although a DEF FN function is designed to return a result, it is more closely related to a GOSUB subroutine in actual operation. Like a GOSUB routine it is invoked with a 3-byte assembly language "near" call, as opposed to the 5-byte "far" call that subprograms and formal functions require. And while a DEF FN function can accept incoming parameters, variables within the function definition are by default shared with the main portion of the program.
As I already explained, variables used in a DEF FN function can be made private to the function only by explicitly declaring them as STATIC. However, at least it is possible to employ local variables. Further, a DEF FN function can return a result, which makes it an ideal replacement for GOSUB when speed is paramount.
Internally, parameters are passed to a DEF FN function very differently than to a called subprogram or formal function. Arguments are passed to a subprogram by placing their addresses on the stack. With a DEF FN function, however, a copy of each parameter is created, and the function directly manipulates those copies. Therefore, it is impossible for a DEF FN function to modify an incoming parameter directly. This behavior is neither good nor bad. Rather, it is simply different and thus important to understand. It is also important to understand that a DEF FN function can be used only in the module in which it is defined. If the same function is needed in different modules, the same code must be duplicated again and again.
In the manuals that come with QuickBASIC and BASIC PDS, Microsoft advises against using DEF FN functions, in favor of the newer, more powerful formal functions. Because of this favoritism, Microsoft will probably never correct one disturbing anomaly that is present in all DEF FN functions. When a string is passed as an argument to a DEF FN function, a copy is made for the function to manipulate. Unfortunately, the copy is never deleted! Therefore, if you pass, say, a 10,000 byte string to a DEF FN function, that amount of memory is permanently taken until the function is invoked again later. The short listing below proves this behavior.
DEF FnWaste (A$) FnWaste = ASC(A$) END DEF Big$ = SPACE$(10000) PRINT FRE(Big$) X = FnWaste(Big$) PRINT FRE(Big$)
Notice that running this program in the QuickBASIC editing environment will not give the expected (memory-wasting) result. However, in a separately compiled program the 10000 byte loss will be evident.
As with subprograms, there is a fixed amount of overhead required to enter and exit a DEF FN function. For each function that has been defined, 5 bytes are needed to call the Enter and Exit routines. Further, these routines are 14 and 24 bytes in length respectively. But again, the routines themselves are added to a program only once when it is linked.
There are two final limitations of DEF FN functions worth mentioning here. The first is that arrays and TYPE variables may not be passed as parameters to them. Since by design a copy is made of every incoming parameter, there is no reasonable way to do that with an entire array. The second limitation is that the function definition must be physically positioned in the source file before any references are made to it.
A formal function is nearly identical to a called subprogram, and it requires the exact same amount of overhead to enter and exit. Also like subprograms, nearly any type of data may be passed to a function, including TYPE variables and arrays. The only limitation is that a fixed-length string may not be used directly as a parameter. If a fixed-length string is passed to a subprogram or function that expects a string, a copy is made and assigned to a conventional string. This copying was described in detail in Chapter 2.
Because a formal function is invoked by referencing its name in an assignment or PRINT statement, it is essential that it be declared. After all, how else could BASIC know that the statement PRINT MyFunc means to call a function and display the result, as opposed to printing the variable named MyFunc? When a BASIC function is created in the BASIC editing environment, a corresponding DECLARE statement is generated automatically. But when a function is written in another language or kept in a Quick Library, an explicit declaration is mandatory.
Like subprograms, formal functions are ideally suited to modular, reusable programming methods. Furthermore, a function may be accessed from any module in an entire application, even those in other source files. Indeed, the only difference between a subprogram and a function is that a function returns a result. The assembly language code that BASIC generates is in all other respects identical.
As I stated earlier, when the STATIC keyword is appended to a SUB or FUNCTION declaration, all of the variables within the routine are assigned a permanent address in DGROUP. And when STATIC is omitted, the variables are instead stored on the stack and cleared to zeros or null strings each time the routine is entered. There are several important ramifications of this behavior. Non-static procedures allocate new stack memory each time they are invoked, and then release that memory when they exit. It is therefore possible to exhaust the available stack space when the subroutine calls are deeply nested.
For example, if you call one subprogram that then calls another which in turns calls yet another, sufficient stack memory must be available for all of the variables in all of the subprograms. Besides the memory needed for each variable in a subprogram or function, other data is also placed onto the stack as part of the call. For each parameter that is passed, 2 bytes are taken to hold its address. Add to that 4 bytes to store the segment and address to return to in the calling program. Finally, temporary variables that BASIC creates for its own purposes are also stored on the stack in a non-static subprogram or function.
Another important consideration when STATIC is omitted is that every string variable must be deleted before the subprogram exits. Because of the way BASIC's string management routines operate, memory that holds string descriptors and string data cannot simply be abandoned. Every string must be released explicitly by a called routine, at a cost of 9 bytes per string. Please understand that you do not have to delete these strings. Rather, this is another case where BASIC creates additional code without telling you.
Again, I would love to be able to tell you that using STATIC is always desirable, or that never using it always makes sense. But unfortunately, it just isn't that simple. When a program becomes very large and complex, only by counting variables can you be absolutely certain how much stack space is really needed. Although the FRE(-2) function may be used to determine how much stack memory is currently available, it does not tell how much memory is actually needed by each routine.
To summarize the trade-offs between static and non-static variables: Static variables are allocated permanently by the compiler, and the memory they occupy can never be used for any other purpose. Non-static variables are placed onto the stack, and exist only while the subprogram or function is in use. Remember that you can also have a mix of static and non-static variables in the same procedure. By omitting STATIC after the subroutine name, all variables will by default be non-static. You can then override that property for selected variables by using the STATIC keyword. In the section on debugging in Chapter 4, you will learn how to use CodeView to determine the stack requirements for a procedure's variables.
There are several ways to control the amount of memory that is dedicated for use by the stack. All versions of BASIC support the CLEAR command, which takes an optional argument that sets the stack size. The statement CLEAR , , StackSize sets aside StackSize bytes for the stack. Unfortunately, CLEAR also clears all of the data in a program, closes any open files, and erases all arrays. If you know ahead of time how much stack memory will be needed, then using CLEAR as the first statement in a program will not cause a problem.
Even when CLEAR is used as the first statement in a program, there is still one situation where that will not be acceptable. When you use CHAIN to execute a subsequent program, a CLEAR statement in that program will clear all of the variables that have been declared COMMON. Fortunately, there are two solutions to this problem: BASIC PDS offers the STACK statement, which lets you establish the size of the stack but without the side effects of CLEAR. For example, the statement STACK 5000 sets aside 5000 bytes for the stack. The other solution is to use the /STACK: link switch, which reserves a specified number of bytes. All of the options that LINK supports are described in Chapter 5.
I have already illustrated some of the situations in which a recursive subprogram or function could be useful. Now lets look at some actual programming examples. The Evaluate function in the listing below uses recursion to reinvoke itself for each new level of parentheses it encounters.
DECLARE FUNCTION Evaluate# (Formula$)
INPUT "Enter an expression: ", Expr$
PRINT "That evaluates to"; Evaluate#(Expr$)
FUNCTION Evaluate# (Formula$)
'Search for an operator using INSTR as a table lookup. If found,
'remember which one and its position in the string.
FOR Position% = 1 TO LEN(Formula$)
Operation% = INSTR("+-*/", MID$(Formula$, Position%, 1))
IF Operation% THEN EXIT FOR
NEXT
'Get the value of the left part, and a tentative value for the
'right part.
LeftVal# = VAL(Formula$)
RightVal# = VAL(MID$(Formula$, Position% + 1))
'See if there's another level to evaluate.
Paren% = INSTR(Position%, Formula$, "(")
'There is, call ourselves for a new RightVal#.
IF Paren% THEN RightVal# = Evaluate#(MID$(Formula$, Paren% + 1))
'No more to evaluate, do the appropriate operation and exit.
SELECT CASE Operation%
CASE 1 'addition
Evaluate# = LeftVal# + RightVal#
CASE 2 'subtraction
Evaluate# = LeftVal# - RightVal#
CASE 3 'multiplication
Evaluate# = LeftVal# * RightVal#
CASE 4 'division
Evaluate# = LeftVal# / RightVal#
END SELECT
END FUNCTION
When you run this program, enter an expression like 15 * (12 + (100 / 8)). To keep the code to a minimum, Evaluate accepts only simple, two-number expressions. That is, it will not work with more than one math operator within each pair of parentheses as in 10 * (3 + 4 + 5). However, the parentheses may be nested to nearly any level.
This function begins by examining each character in the incoming formula string for a math operator. If it finds one the operator number (1 through 4) is remembered, as well as its position in the formula string. Next, VAL is used to obtain the value of the digits to the left of the operator, as well as the digits to the right. Notice that it was not necessary to use LEFT$ to isolate the left-most portion of the string, because VAL stops examining the string when it encounters any non-digit character such as the "+" or "(".
Once these values have been saved, the next test determines if any more parentheses follow in the formula. If so, Evaluate calls itself, passing only those characters that are beyond the next parenthesis. Thus, the same routine evaluates each new level, returning to the level above only after all levels have been examined. I encourage you to run this program in the QuickBASIC editing environment, and step through each statement one by one with the F8 Trace command. In particular, use the Watch Variable feature to view the value of Position% and LeftVal# as the function recurses into subsequent invocations.
It is important to understand the need for stack variables in this program, and why STATIC must not be used in the function definition. When Evaluate walks through the incoming string and determines which math operator is specified, that operator must be remembered throughout the course of the function. If a static variable were used for Operation%, then its previous value would be destroyed when Evaluate calls itself. Likewise, LeftVal# cannot be overwritten either, or it would not hold the correct value when Evaluate returns to itself from the level below. Therefore, as you step through this program you will observe that each new invocation of Evaluate creates a new set of variables.
As you can see, stack variables are necessary for the proper functioning of a subprogram or function that calls itself. They are also necessary when one procedure calls another procedure which in turn calls the first one again. The key point is that each time a non-static routine is invoked, new and unique variables must be created. Otherwise, the variable contents from a previous level above will be overwritten.
Although recursion is a powerful and necessary technique, it should be used only when necessary. There is a substantial amount of overhead needed to allocate stack memory and clear it to zeros, so invoking a non-static routine is relatively slow. And as I described earlier, every non-static string variable must be deleted when the routine exits, at a cost of 9 bytes apiece.
Some programmers use recursion even when there are other, more efficient ways to solve a problem. For example, the QuickBASIC manual shows a recursive function that calculates a factorial. (A factorial is derived by multiplying a number by all of the whole numbers less than itself. That is, the factorial of 4 equals 4 * 3 * 2 * 1.) However, a factorial can be calculated faster and with less code using a simple FOR/NEXT loop as shown below. This version of Factorial is 20 percent faster than the example given in the QuickBASIC manual.
FUNCTION Factorial#(Number%) STATIC
Seed# = 1
FOR X% = 1 TO Number%
Seed# = Seed# * X%
NEXT
Factorial# = Seed#
END FUNCTION
As you have already learned, BASIC normally passes data to a subprogram or function by placing its address on the stack. And when an entire array is specified, the address of the array descriptor is sent instead. But there are some cases where BASIC imposes restrictions on how variables and arrays may be passed to a procedure. Let's look now at some of the ways to get around those restrictions.
When using versions of BASIC earlier than PDS 7.1, it is not legal to pass an array of fixed-length strings. In fact, it is also impossible to pass a single fixed-length string directly. As you saw in Chapter 2, BASIC copies every fixed-length string argument to a regular string, which adds a lot of code and also wastes string memory.
The simplest solution for fixed-length strings is to define an equivalent TYPE that is comprised of a single string component. Since a TYPE variable or array can legally be passed, this is the easiest and most direct approach, as shown here.
TYPE FLen S AS STRING * 100 END TYPE DIM MyString AS Flen CALL Subprogram(MyString) SUB Subprogram(FLString AS FLen) ... ... END SUB
If the subprogram being called is in a separate module, then the TYPE definition must also be present in that file. However, the DIM statement is needed only in the program that passes the string. This also works with fixed-length string arrays, except that the DIM would have to be changed to DIM MyArray(1 TO NumElements) AS FLen, and the subprogram's definition would be changed to SUB Subprogram(FLString() AS FLen).
BASIC PDS 7.1 supports passing a fixed-length string array directly, so this work-around is not needed with that version. Curiously, a single fixed-length string may not be passed as a parameter in BASIC 7.1. Since a fixed-length string is closely related to a TYPE variable, this limitation seems arbitrary at best.
BASIC 7.1 also supports the use of BYVAL when passing numeric arguments to procedures. This is a particularly powerful feature, because it can greatly reduce the amount of code needed to access those values within the routine. It also eliminates the need to make copies when a constant is passed as an argument. To take advantage of this feature, you simply specify BYVAL in both the calling and receiving argument list, as shown below.
DECLARE SUB Subroutine(BYVAL Arg1%, BYVAL Arg2%) CALL Subroutine(Var1%, Var2%) SUB Subroutine(BYVAL X%, BYVAL Y%) ... ... END SUB
Because the actual value of the argument is being passed, there is no way to return information back to the caller. But in those situations where an assignment to the original variable from within the routine is not needed, BYVAL can eliminate a lot of compiler-generated code when dealing with integers. Of course, you may use a mix of BYVAL and non-BYVAL parameters if you need the benefits of both methods in a single call.
As proof of this savings, disassemblies of a one-statement subprogram designed both ways is presented below, to show how an integer parameter is accessed when it is passed by address and by value.
SUB ByAddress(Param%) STATIC LocVar% = Param% MOV SI,[Param%] ;get the address of Param% MOV AX,[SI] ;then read the value there MOV LocVar%,AX ;assign that to LocVar% END SUB SUB ByValue(BYVAL Param%) STATIC LocVar% = Param% MOV AX,Param% ;read Param% directly MOV LocVar%,AX ;and assign it to LocVar% END SUB
Note that the savings are only within the subroutine, and not when it is called. That is, 4 bytes are needed to pass an integer variable whether by address or by value. In fact, passing larger data types requires more code to pass by value. Any variable can be passed by address with 4 bytes of compiler-generated code, because what is sent is a single address. But to pass a double precision number by value requires 16 bytes, since 4 bytes of code are needed for each 2-byte portion of the number.
In general, passing variables as parameters to a subprogram or function is preferable to sharing them. When many variables are shared throughout a program, you run the risk of introducing bugs caused by accidentally using the same variable name more than once. However, sharing has some definite advantages in at least two situations.
The first is when a procedure must be accessed as quickly as possible. Since a finite amount of code is needed to pass each parameter, some amount of time is also required to execute that code. Therefore, sharing a few, carefully selected variables can improve the speed of your programs and reduce their size as well. Another important use for SHARED is to conserve data memory. Nearly all programs use at least a few temporary scratch variables, perhaps as FOR/NEXT loop counters. By dimensioning several such variables as being shared throughout a program, the same variables can be used repeatedly. I often begin programs with a DIM SHARED statement such as DIM SHARED X, Y, Z, and then use those variables as often as possible.
One final trick I want to share is how to pass a large number of parameters using less code than would normally be necessary. Each argument that is passed to a procedure requires 4 bytes of code. In a complicated routine that needs many parameters, this can quickly add up. Worse, these bytes are added for every call. Therefore, a subprogram that accepts 10 parameters and is called 20 times will add 800 bytes to the final executable file just to handle the parameters!
One solution is to use an array, which is ideal when all of the parameters are the same type of data. An entire array can be passed as a single parameter since only the array descriptor's address is needed. Even better, however, is to create a TYPE variable, and then assign all of the parameters to it. A TYPE variable can hold nearly any amount and type of data, and it too can be passed using only 4 bytes. Although this does require a separate assignment for each TYPE component, you simply use the TYPE where the regular variables would have been assigned. By eliminating the added code to pass many parameters, programs that use a TYPE this way will also be much faster.
QuickBASIC versions 4.0 and later let you load subprograms and functions from multiple files into the editing environment at the same time. This further enhances their reusability, since the different modules can be treated as "black boxes" whose purpose is already known. Once a routine has been developed and debugged, it can be used again and again, without further regard for the names of the variables within the routines. Indeed, many of the utility routines included with this book are provided as separate modules, intended to be loaded along with your programs.
Any variable name can be passed as an argument to a procedure, even if a different name is used to represent the same variable within the procedure. If you have defined a subprogram such as SUB MySub(X%, Y!, Z$), then you could call it using CALL MySub(A%, B!, C$). Of course, the variables you pass must be of the same data type as the subroutine expects.
Because reusability is an important consideration in the design of any procedure, it generally makes sense to store it in its own source file. This lets you combine the same module repeatedly with any number of programs. The alternative would be to merge the file into each program that needs it. But maintaining multiple copies of the same code wastes disk space. Further, if a bug is found in the routine, you will have to identify all of the programs that contain it, and manually correct each one of them.
Another important advantage of using separate files is that you can exceed the usual 64K code size barrier. Unlike the data segment which is comprised of the sum of all data in all modules, an .EXE file can contain multiple code segments. Each BASIC module has a single code segment, and each of these can be as large as 64K. In fact, dividing a program into separate files is the *only* way to exceed the usual 64K code size limitation.
Although using a separate source file for each subprogram makes sense in many situations, there is one slight disadvantage. When all of the various program modules are linked together, each separate module adds approximately 100 bytes of overhead. None the less, for all but the smallest programming projects, the advantages of using separate modules will probably outweigh the slight increase in code size.
Another useful BASIC feature that can help you to create modular programs is the Include file. An Include file is a separate file that is read and processed by BASIC at a specified place in your program. The statement '$INCLUDE: 'filename' tells QB or BC to add the statements in the named file to your source code, as if that code had been entered manually. If a file extension is not given, then .BAS is assumed. Many of the files that Microsoft provides with QuickBASIC use a .BI extension, which stands for "BASIC Include". Some programmers use .INC, and you may use whatever seems appropriate to the contents of the file.
Include files are ideal for storing DECLARE, CONST, TYPE, and COMMON statements. Except for COMMON, none of these statements add to the size of your program, and none of them create any executable code. Therefore, you could create a single include file that is used for an entire project, and add an appropriate '$INCLUDE directive to the beginning of each program source file. Unused DECLARE and CONST statements and TYPE definitions are ignored by BASIC if they are not referenced. However, they do impinge slightly on available memory within the QuickBASIC editor, since BASIC has no way to know that they are not being used. Similarly, BC must keep track of the information in these statements as it compiles your program. But again, there is no impact on the size of your final executable program.
In general, I recommend that you avoid placing any executable statements into an include file. Because the code in an include file is normally hidden from your view, it is easy to miss a key statement that is causing a bug. Likewise, a '$DYNAMIC or '$STATIC command hidden within an include file will obscure the true type of any arrays that are subsequently dimensioned. Perhaps worst of all is placing a DEFINT or other DEFtype statement there, for the same reason.
Quick Libraries contribute to modular programming in two important ways. Perhaps the most important use for a Quick Library is to allow access to subprograms and functions that are not written in BASIC. All DOS programs and subroutines--regardless of the language they were originally written in--end up as .OBJ files suitable for LINK to join together. But the QB and QBX editing environments manipulate BASIC source code, and interpret the commands rather than truly compile them. Therefore, the only way you can access a routine written in assembly language or C within QuickBASIC is by placing the routine into a Quick Library.
Quick Libraries also let you store completed BASIC subprograms and functions out of the way from the rest of your program. If you have a large number of subroutines in one program, the list of names displayed when F2 is pressed can be very long and confusing. Since QuickBASIC does not display the routines in a Quick Library, there will be that many fewer names to deal with. Another advantage of placing pre-compiled BASIC routines into a Quick Library is that they can take less memory than when the BASIC source code is loaded as a module. This is true especially when you have many comments in the program, since comments are of course not compiled.
Be aware that there are a few disadvantages to placing BASIC code into a Quick Library. One is that you cannot step and trace through the code, since it is not in its original BASIC source form. Another is that Quick Libraries are always stored in normal DOS memory, as opposed to expanded memory which QBX [and VB/DOS] can use. When a BASIC subprogram or function is less than 16K in size and EMS is present, QBX [and VB/DOS] will place its source code in expanded memory to free up as much conventional memory as possible.
As a BASIC programmer, there are several types of errors that you must deal with in a program. These errors fall into two general categories: compile errors and runtime errors. Compile errors are those that QB or BC issue, such as "Syntax error" or "Include file not found". Generally, these are easy to understand and correct, because the QuickBASIC editor places the cursor beneath the offending statement. In some cases, however, the error that is reported is incorrect. For example, if your program uses a function in a Quick Library that expects a string parameter and you forgot to declare it, BASIC reports a "Type mismatch" error. After all, with a statement such as X = FuncName%(Some$), how could BASIC know that FuncName% is not simply an integer array? Assuming that it is an array, BASIC rejects Some$ as being illegal for an element number.
Runtime errors are those such as "File not found" which are issued when your program tries to open a file that doesn't exist, or is not in the specified directory. Other common runtime errors are "Illegal function call", "Out of string space", and "Input past end". Many of these errors can be avoided by an explicit test. If you are concerned that string space might be limited you can query the FRE("") function before dimensioning a dynamic string array. However, some errors are more difficult to anticipate. For example, to determine if a particular directory exists you must use CALL Interrupt to query a DOS service.
The conventional way to handle errors is to use ON ERROR, and design an error handling subroutine. There are a number of problems with using ON ERROR, and most professional programmers try to avoid using it whenever possible. But ON ERROR does work, and it is often the simplest and most direct solution in many programs. The short listing below shows the minimum steps necessary to implement an error handler using ON ERROR.
ON ERROR GOTO HandleErr FILES "*.XYZ" END HandleErr: SELECT CASE ERR CASE 53: PRINT "File not found" CASE 68: PRINT "Device unavailable" CASE 71: PRINT "Disk not ready" CASE 76: PRINT "Path not found" CASE ELSE: PRINT "Error number"; ERR END SELECT RESUME NEXT
The statement ON ERROR GOTO HandleErr tells BASIC that if an error occurs, the program should jump to the HandleErr label. Without ON ERROR, the program would display an error message and then end. Since it is unlikely that you have any files with an .XYZ extension, BASIC will go to the error handler when this program is run. Within the error handling routine, the program uses the ERR function to determine the number of the error that occurred. Had line numbers been used in the program, the line number in which the error occurred would also be available with the ERL function.
In this brief program fragment, the most likely error numbers are filtered through a SELECT CASE block, and any others will be reported by number. Regardless of which error occurred, a RESUME NEXT statement is used to resume execution at the next program statement. RESUME can also be used with an explicit line label or number to resume there; if no argument is given BASIC resumes execution at the line that caused the error. In many cases a plain RESUME will cause the program to enter an endless loop, because the error will keep happening repeatedly.
In this case, the file will not exist no matter how many times BASIC tries to find it. Therefore, a plain RESUME is not appropriate following a "File not found" or similar error. Had the error been "Disk not ready", you could prompt the user to check the drive and then press a key to try again. In that case, then, RESUME would make sense. Although BASIC's ON ERROR can be useful, it does have a number of inherent limitations.
Perhaps the worst problem with ON ERROR is that it often increases the program's size. When you use RESUME NEXT, you must also use the /x compile switch. Unfortunately, /x adds internal address labels to show where each statement begins, so the RESUME statement can find the line that caused the error. These labels are included within the compiled code and therefore increases its size.
Another problem with ON ERROR is that it can hide what is really happening in a program. I recommend strongly that you REM out all ON ERROR statements while working in the QuickBASIC editing environment. Otherwise, an Illegal function call or other error may cause QuickBASIC to go to your error handler, and that handler might ignore it if the error is not one you were expecting and testing for. If that happens and your program uses RESUME NEXT, you might never even know that an error occurred!
Yet another problem with ON ERROR is that it's frankly a clumsy way to program. Most languages let you test for the success or failure of the most recent operation, and act on or ignore the results at your discretion. Pascal, for example, uses the IOResult function to indicate if an error occurred during the last input or output operation.
Finally, BASIC generates errors for many otherwise proper circumstances, such as the FILES statement above. You might think that if no files were found that matched the .XYZ extension given, then BASIC would simply not display anything. Indeed, an important part of toolbox products such as Crescent Software's QuickPak Professional are the routines that replace BASIC's file handling statements. By providing replacement routines that let you test for errors without an explicit ON ERROR statement, an add-on library can help to improve the organization of your programs.
As I mentioned earlier, some errors can be avoided by using CALL Interrupt to access DOS directly. (One important DOS service lets you see if a file exists before attempting to open it.) But critical errors such as those caused by an open drive door require assembly language. In Chapter 11 you will learn how to bypass BASIC and access DOS directly using CALL Interrupt.
BASIC includes several forms of event handling, and like ON ERROR, these too are avoided when possible by many professional programmers. Event handling lets your programs perform a GOSUB automatically and without any action on your part, based on one or more conditions. Some of the more commonly used event statements are ON KEY, ON TIMER, and ON COM. With ON KEY, you can specify that a particular key or combination of keys will temporarily halt the program, and branch to a GOSUB routine designated as the ON KEY handler. ON TIMER is similar, except it performs a GOSUB at regular intervals based on BASIC's TIMER function. Likewise, ON COM performs a GOSUB whenever a character is received at the specified communications port.
The concept of event handling is very powerful indeed. For example, ON COM allows your program to go about its business, and also handle characters as they arrive at the communications port. ON TIMER lets you simulate a crude form of multi-tasking, where control is transferred to a separate subroutine at one second intervals. Unfortunately, BASIC's event handling is not truly interrupt driven, and the resulting code to implement it adds considerably to a program's size.
When any of the event handling methods are used, BASIC calls an interval event dispatcher periodically in your program. These calls add five bytes apiece, and one is added at either every statement, or at every labeled statement [depending on whether you compiled using /v or /w respectively]. This can increase your program's size considerably. Even worse, the repeated calls have an adverse effect on the speed of most programs. Like ON ERROR, BASIC's event handling statements provide a simple solution that is effective in many programming situations. And also like ON ERROR, they are best avoided in important programming projects.
Using purely BASIC techniques, the only alternative to event trapping is polling. Polling simply means that your program manually checks for events, instead of letting BASIC do it automatically. The primary advantage of polling is that you can control when and where this checking occurs. The disadvantage is that it requires more effort by you.
To see if any characters have been received from a communications port but are still waiting to be read you would use the LOF function. And to see if a given amount of time has elapsed you must query the TIMER function periodically. If true interrupt driven event handling were available in BASIC, that would clearly be preferable to either of the two available methods. However, only with Crescent's P.D.Q. product can such capability be added to a BASIC program.
Programming style is a personal issue, and every programmer develops his or her own particular methods over time. Some aspects of programming style have little or no impact on the quality of the final result. For example, the number of columns you indent a FOR/NEXT loop will not affect how quickly a sort routine operates. But there are style factors that can help or harm your programs. One is that clearly commenting your code will help you to understand and improve it later. Another is when more than one programmer is working on a large project simultaneously. If neither programmer can figure out what the other is doing, the program's quality will no doubt suffer.
Clearly, no one can or even should try to force a particular style or ideology upon you. However, I would like to share some of the decisions that I have made over the years, and explain why they make sense to me. Of course, you are free to use or not use these opinions as you see fit. Programmers are as unique and varied as any other discipline, and no one set of rules could possibly serve everyone equally. Whatever conventions you settle upon, be consistent above all else.
The most important convention that I follow is to use DEFINT A-Z as the first statement in every program. For me, using integers verges on religion, and my fingers could type DEFINT even if I were asleep. As I have stated repeatedly, integers should be used whenever possible, unless you have a compelling reason not to. Integers are much faster and smaller than any other variable type BASIC offers. Nearly all of the available third party add-on products use integers parameters wherever possible, and so should the routines you write. The only reasonable exception to this is when writing financial or scientific programs, or other math-intensive applications.
Equally important is adding sufficient and appropriate comments. Some programmers like to use comment headers that identify each related block of code; others prefer to comment every line. I recommend doing both, especially if other people will be reading your programs. I also prefer using an apostrophe as a comment delimiter, rather than the more formal REM. There are only so many columns available for each comment line, and it seems a shame to waste the space REM requires.
When writing a subprogram or function that you plan to use again in other projects, include a complete heading comment that shows the purpose of the routine and the parameters it expects. If each parameter is listed neatly at the beginning of the file, you can create a hardcopy index of routines by printing that section of each file.
Avoid comments that are obvious or redundant, such as this:
Count = Count + 1 'increment Count
If Count is keeping track of the number of lines read from a file, a more appropriate comment would be 'show that another line was read. Also avoid comments that are too cute or flip. Simply state clearly what is happening so you will know what you had in mind when you come back to the program next month or next year.
Selecting meaningful variable names is equally valuable in the overall design of a program. If you are keeping track of the current line in a file, use a variable name such as CurLine. Although BASIC in some cases lets you use a reserved word as a variable name, I recommend against that. Over the years, different versions of BASIC have allowed or disallowed different keywords for variables. While QuickBASIC 4.5 lets you use Name$ as a variable, there is no guarantee that the next version will. Also, be aware that variables names which begin with the letters Fn are illegal, because BASIC reserves that for user-defined functions. Using the variable FName$ to hold a file name may look legal, but it isn't.
Don't be ashamed to use GOTO when it is appropriate. There are many places where GOTO is the most direct way to accomplish something. As I showed earlier in this chapter, GOTO when used correctly can sometimes produce smaller and faster code than any other method.
Use line labels instead of line numbers. The statement GOSUB 1020 doesn't provide any indication as to what happens at line 1020. GOSUB OpenFile, on the other hand, reads like plain English. The only exception to this is when you are debugging a program that crashes with the message "Illegal function call at line no line number". In that case, you should *add* line numbers to your program and run it again. A program that reads a source file and prints each line to another file with sequential numbers is trivial to write. I will also discuss debugging in depth in Chapter 4.
Even though using DEFINT is supposed to force all subsequent CONST, DEF FN, and FUNCTION declarations to be integer, a bug in QuickBASIC causes untyped names to occasionally assume the single precision default. Therefore, I always use an explicit percent sign (%) to establish each function's type. In fact, I use whatever type identifier is appropriate for functions and CONST statements, to make them easily distinguishable in the program listing. For example, in the statement IF CurRow > MaxRows% THEN CurRow = MaxRows%, I know that MaxRows% has been defined as a constant. Some people prefer to use all upper-case letters for constants, though I prefer to reserve upper case for BASIC keywords.
Although BASIC supports the optional AS INTEGER and AS SINGLE directives when defining a subprogram or function, that wastes a lot of screen space. I greatly prefer using the variable type identifiers. That is, I will use SUB MySub(A%, B!) rather than SUB MySub(A AS INTEGER, B AS SINGLE). The same information is conveyed but with a lot less effort and screen clutter.
A well-behaved subroutine will restore the PC to the state it was when called. If you have subprogram that prints a string centered on the bottom line of the screen, use CSRLIN and POS(0) to read the current cursor location before you change it. Then restore the cursor before you exit.
I like to indent two spaces within FOR/NEXT and IF/THEN blocks. Although some people prefer indenting four or even eight columns for each level, that can quickly get out of hand when the blocks are deeply nested. Nothing is harder to read than code that extends beyond the edge of the screen. But whatever you do, please *do not* change the tab stop settings in the QuickBASIC editor, unless you are the only one who will ever have to look at your code. Even though the program may look fine on your screen, the indentation will be completely wrong on everyone else's PC.
When creating a dynamic array I prefer REDIM to a previous '$DYNAMIC statement. REDIM is clearer because it shows at the point in the source where the array is dimensioned that this is a dynamic array. Otherwise you have to scan backwards through your source code looking for the most recent '$DYNAMIC or '$STATIC, to see what type of array it really is. By the same token, using ever-changing DEFtype statements throughout your code is poor practice. Further, if a variable is a string, always include the dollar sign ($) suffix when you reference it. If you use DEFSTR S or even worse, DIM xxx AS STRING and then omit the dollar sign, nobody else will understand your program.
I also prefer to explicitly dimension all arrays, and not let BC create them with the 11-element default (including element zero). If you need less than 11 elements, the memory is wasted. And if you need more, then your program will behave unpredictably. Not dimensioning every array is sloppy programming. Period.
Avoid repeated calls to BASIC's internal functions if possible. In the listing below, the first example creates 61 bytes of code, while the second generates only 46 bytes.
Not recommended:
IF CSRLIN = 1 OR CSRLIN = 6 OR CSRLIN = 12 THEN ... END IF
Much better:
Temp = CSRLIN IF Temp = 1 OR Temp = 6 OR Temp = 12 THEN ... END IF
As I stated earlier in this chapter, using SELECT CASE instead of IF will also eliminate this problem. Many BASIC statements are translated into calls, and each call takes a minimum of five bytes.
Your programs will be easier to read if you evaluate temporary expressions separately. Even though BASIC lets you nest parentheses to nearly any level, nothing is gained by packing many expressions into a single statement. In the examples below that strip the extension from a file name, the first creates only a few bytes less code. Although this may seem counter to the other advice I have given, a slight code increase is often more than offset by a commensurate improvement in clarity.
File$ = LEFT$(File$, INSTR(File$, ".") - 1) Dot = INSTR(File$, ".") File$ = LEFT$(File$, Dot - 1)
The last issue I want to discuss is how to pronounce BASIC keywords and variable names. Don't laugh, but many programmers have no idea how to communicate the words LEFT$ or VARSEG over the telephone. Some people say "X dollar" for X$ even though "X string" is so much easier to say. Another keyword that's hard to verbalize is VARPTR. I prefer "var pointer" since it is, after all, a pointer function. CHR$(13) is pronounced "character string thirteen", again because that's the clearest and most straight forward interpretation. Likewise, INSTR is pronounced "in string" and LEFT$ would be said as "left string". If you're not sure how to pronounce something, use the closest equivalent English wording you can think of.
In this chapter you have learned how BASIC's control flow statements are constructed, and how the compiler-generated code is similar regardless of which statements are used. You also learned where GOSUB and GOTO should be used, and when subprograms and functions are more appropriate. The discussion on logical operations showed how AND, OR, EQV, and XOR operate, and how they can be used to advantage in your programs.
I have explained in detail exactly what recursion is, and how recursive subroutines can perform services that are not possible using any other technique. You have also learned about the importance of the stack in recursive and other non-static subroutines. Passing parameters to subprograms and functions has also been described in detail, along with some of the principles of modular program and event handling.
Finally, I have shared with you some of my own personal preferences regarding programming style, and when and how such conventions can make a difference. Although this is a personal issue, I firmly believe it is important to develop a consistent style and stick with it.
In Chapter 4 you will learn debugging methods using both the QuickBASIC editing environment and Microsoft's CodeView debugger. The successful design of a program is but one part of its development. Once it has been written, it must also be made to work correctly and reliably. As you will learn, there are many techniques that can be used to identify and correct common programming errors.
by Zip <zippy_@hotmail.com>
In this tutorial, I will explain the math behind making a simple ripple effect, and hopefully provide a working demonstration. I can't think of any practical application of such an effect beyond just a nice graphics demo, but it's quite nice, nonetheless. We will start with the one dimensional case, then build upon that for a 2D implementation. It is assumed that your are no less than an intermediate programmer and that you have a solid background in math (specifically trigonometry and algebra), though the topics discussed here should be easily understood. All I know of this effect is what I found on my own, so it's not guaranteed to be physically accurate in any way. But it looks neato. ;)
The ripple follows a sine wave, and the amplitude of the wave decreases as the distance from the origin increases. The viewer looks directly down at the wave, and the light ray is refracted by .5 pi radians from the angle of the instantaneous slope of that point. So we just take the inverse of the instantaneous slope, and project that to the X axis. Perhaps a few diagrams will help.
y^ pi/2 y = sin x | | | . . | . . | . . | . . | . . | . . pi radians 2 pi radians |. . / \ ..---------------------.----------------------.-> x |\ . . | 0 . . | . . | . . | . 3pi/2 . | . | . | . . | v
As you can see, the slope of the curve is steepest at x = 0 and x = pi, and least steep at x = pi/2 and x = 3pi/2. Also, notice that the instantaneous slopes of the curve range from 1 to -1, as do the values of the sine function, and that the instantaneous slope when x = 0 is 1, 0 at x = pi/2, etc.
And here's the cosine function:
y^ y = cos x | |. . |\ . . \ | 0 . . 2pi | . . | . . | . pi/2 3pi/2 . | . / \ . +----------.----------------------.-----------------> x | . . | . . | . . | . . | . pi . | . | . | . . | v
As you can probably see, the cosine function is the instantaneous slope (or first derivative, I believe) of the sine function. Now let's look at how light is refracted in a wave. The method I will describe here makes a big assumption, and neglects the fact that different liquids may refract light differently than others. However, this is generally good enough for our purposes. Let's say that a light ray going straight down to the wave is refracted at 90 degrees, or pi/2 radians, to the instantaneous slope at that point. The ray is then projected to the X axis. For example:
y^ <O> / | | / -instantaneous slope | | / . . | | /. . | | / . | |. inverse of . | .\ / instantan- . | / \ eous slope . |/ \ . ..-----\---------------.----------------------.-> x | . . | . . | . . | . . | . . | . . | . . | v
Now let's move the sine wave up a bit, since the X axis will be our background picture, and wave usually don't go below the solid object under the liquid. The distance we move the graph of the sine wave upward will be the depth of the liquid, which I will call d.
y^ y = d + sin x | | . . | . . | . . | . . | . . | . . |. . .. . . -+ | . . | | . . | | . . | | . . | | . . +- d | . . | | . . | | | | | |-----------------------------------------------> x -+ v
Now we need a formula to project the vector to the X axis. We shall derive this formula from the equation for a line, y=mx+b. First, let's consider what's given, what we've already figured out, and what remains to be solved. x1 is given, and y1 is the sine of X plus the depth. y2 is always 0, since it's being projected to the X axis. m1 is the inverse of the instantaneous slope of the line, which is one divided by the cosine of X, and m2 is the same value. Now you may be wondering how we would calculate b, the Y intercept. All we need to do with that is express it in terms of x, y, and m. The Y intercept can be expressed as y1-mx. Now I shall solve the equations for x2.
First, a few variable definitions:
x = x1 m = m1 = m2 = 1 / cos(x) y = y1 = d + sin(x) y2 = 0 u = x2 b = b1 = b2 = y - mx
Now the derivation:
y1 = m1*x1 + b1 y = mx + b y - b = mx (y - b) / x = m y2 = m2*x2 + b2 0 = mu + b -b = mu -b/u = m ..�. (y - b) / x = -b/u (u(y - b)) / x = -b u(y - b) = -bx u = -bx / (y - b) u = ((-y-mx)x) / (y - (y-mx)) u = -((y-(x/cos(x)))x) / (y - (y-(x/cos(x)))) u = -((y-(x/cos(x)))x) / (x/cos(x)) u = -(cos(x)(y-(x/cos(x)))x) / x u = -cos(x)(y - (x / cos(x))) u = -cos(x)y - (x*cos(x))/cos(x) u = -(cos(x)y - x) u = x - cos(x)y u = x - cos(x)(d + sin(x))
I hope that wasn't too hard to follow. You may be asking what good this is, as it obviously can't be used for a ripple effect with a background. Therefore, we shall use what we derived here to develop routines for the 2D case, which will appear 1D as it will be displayed here, but could undoubtedly be utilized in a 3D engine without too much trouble. If it still doesn't make sense, however, then run this little program. It is a graphic illustration of what we're doing here.
SCREEN 12
PI = 3.14159
DEG = PI / 180
DIM BG(639) AS INTEGER
FOR A = 0 TO 639
BG(A) = 1 + RND * 14
PSET (A, 440), BG(A)
NEXT A
FOR X = 0 TO PI * 200
XX = X / 100
YY = SIN(XX)
Y = 240 - YY * 200
XX2 = XX + (1 + SIN(XX)) * COS(XX)
X2 = XX2 * 100
LINE (X, Y)-(X2, 440), 8, , &HAAAA
LINE (X, 0)-(X, Y), 8, , &HAAAA
IF X2 >= 0 AND X2 <= 639 THEN PSET (X, Y), BG(X2)
WAIT &H3DA, 8
WAIT &H3DA, 8, 8
LINE (X, Y)-(X2, 440), 0
LINE (X, 0)-(X, Y), 0
IF X2 >= 0 AND X2 <= 639 THEN
PSET (X, Y), BG(X2)
PSET (X2, 440), BG(X2)
END IF
NEXT X
What?! All that work for one little formula?? That's right. Also, you may have noticed that the above program uses the formula u=x+(d+sin(x))cos(x) instead of u=x-(d+sin(x))cos(x). This is because the positive direction is down instead of up on the computer screen. Now maybe it makes a little more sense, but if you're still confused, then just read all that again until you understand it.
Although I'm calling this the 2D case, it's actually 3D, because the wave moves up and down in the 3rd dimension. For simplicity, I'm going to call the horizontal axis the X axis, the vertical the Y axis, and the axis going directly into the screen the Z axis, though this is not how they are normally named in math classes. To try to help you visualize how the wave would appear in 3D space, look at the picture below.
y ^
|
|
|
|
|
|
.....
..ooooo..
.ooOOOOOoo.
.oOOoooooOOo.
.oOoo.....ooOo.
.oOo.. | ..oOo.
<------------------.oOo.---+---.oOo.------------------> x
.oOo.. | ..oOo.
.oOoo.....ooOo.
.oOOoooooOOo.
.ooOOOOOoo.
..ooooo..
.....
|
|
|
|
|
|
v
Notice that the ripple will be along a single plane, but won't be right on it. That's why I'm calling it 2D and 3D at the same time. In the 1D case, the height of the wave was the sine of the distance from the origin, which was X. However, in 2D, the distance of a point from the origin is the square root of the sum of the squares of the x and y values because of the Pythagorean theorem (z = sqr(x�+y�)). The next part may get a tiny bit confusing, but not terribly so. You may remember that the angle of a vector is equal to the arctangent of its slope, so we have theta=arctan(y/x). What we want is a 2D vector that will point to the correct point on our background picture after being refracted through the sine wave. I'll call the x & y components of this vector u & v, respectively. From the 1D case, we know that:
s = d - y/m
where s is displacement, d is distance along the X or Y axis, m is the inverse of the instantaneous slope of that point, and y is the height of the wave at that point. Now we shall solve this equation for the X and Y components. But before we do that, let's think about what notation to use. We have a vector to the point before refraction in polar notation (angle & magnitude), but we need rectangular coordinates for the final vector. Therefore, we can express the vector from the origin to the point on the wave as:
V = (sqr(x�+y�)cos(arctan(y/x)))i + (sqr(x�+y�)sin(arctan(y/x)))j
So what did that accomplish? Good question. Er, oh yeah. Think about it. When you refract a light ray, its angle in the plane of the ripple does not change; only its vertical angle will change. Therefore, all we have to do is calculate how much this vertical angle changes and project it to the x-y plane. Now, solving the equation above for s:
s = d - y/m
s = sqr(x�+y�) - (d + sin(sqr(x�+y�)))cos(sqr(x�+y�))
^
(depth)
What is this exactly, you ask? It is the magnitude of the vector after refraction. But what's the angle? It's the same as it was before, because the angle in the x-y plane does not change. Using this new magnitude, we get the vector:
V = ((sqr(x�+y�) - (d + sin(x�+y�))cos(x�+y�))cos(arctan(y/x)))i
+ ((sqr(x�+y�) - (d + sin(x�+y�))cos(x�+y�))sin(arctan(y/x)))j
Ok, I know that looks really nasty and complicated at first, but it's really not that bad. All I did is take apply the concepts from the 1D case to the 2D case.
This part is quite simple. All you do is scan an area of pixels around the origin and run the coordinates through those formulas. Keep in mind that the values can be negative, so you will want to add some value (i.e. half the size of the screen) to the values calculated. Pseudo-code would be:
for y = -100 to 100
for x = -100 to 100
u = (sqr(x�+y�) - (d + sin(sqr(x�+y�)))*cos(sqr(x�+y�)))*cos(atn(y/x))
v = (sqr(x�+y�) - (d + sin(sqr(x�+y�)))*cos(sqr(x�+y�)))*sin(atn(y/x))
if (point(u+100,v+100) is on the screen) {
plot x+100, y+100, BGpic(u+100,v+100)
}
next x
next y
Ah, yes. I can hear you screaming now.. "You said you were gonna teach how to make a ripple, but this doesn't even move!". Ok. All we need to do for that is have a variable (w) that is decremented each frame and added to the magnitude used to calculate the sine & cosine in the magnitude of the vector:
u = (sqr(x�+y�) - (d + sin(sqr(x�+y�)+w))*cos(sqr(x�+y�)+w))*cos(atn(y/x)) v = (sqr(x�+y�) - (d + sin(sqr(x�+y�)+w))*cos(sqr(x�+y�)+w))*sin(atn(y/x))
Also, remember that the amplitude of the wave decreases as the magnitude increases. I will say that variable n is equal to the magnitude of the unrefracted ray (sqr(x�+y�)), or one if the magnitude is zero. You may also wish to have a maximum amplitude (a) other than one. Changing the above formulas to reflect these changes give us:
u = (sqr(x�+y�) - (d + a * (sin(sqr(x�+y�)+w) / n)) * a * cos(sqr(x�+y�)+w)) * cos(atn(y/x)) v = (sqr(x�+y�) - (d + a * (sin(sqr(x�+y�)+w) / n)) * a * cos(sqr(x�+y�)+w)) * sin(atn(y/x))
That's right, but there are a few things that can be optimized. Notice that the only difference between the formulas for u & v are that u is the magnitude multiplied by the cosine of the angle while v is the magnitude multiplied by the sine. Therefore, you only have to calculate the magnitude once. You can also use look-up tables for the sine and cosine. The magnitude of the unrefracted vector (sqr(x�+y�)) needs to be calculated only once, as well. Finally, you will definitely want to use an assembly language library to gain as much speed as possible. Double-buffering will help you to gain some speed, too. Even with all this, it will not run too quickly unless you have a fast computer or find more optimizations. It may help if you make the ripple be only a small part of the screen, since redrawing the entire screen one pixel at a time can be very slow.
I changed my mind. I'm only going to give you pseudo-code, as that increases the chances of you understanding the concepts presented before making a working example. If you want to see my ripple demo, go to http://www.angelfire.com/co/zippy15/wtrz.zip. [Editor's Note: The ripple demo is included in the downloadable version of this issue, in the file named ripple.zip]
set graphics mode
dim buffer1(sizeOfScreen), buffer2(sizeOfScreen)
loadPicTo "background.bmp", addressOf(buffer)
w = 0
do {
w = w - 1 degree (pi/180 radians)
if w < 0 then w = 360 degrees (2pi radians)
for y = top to bottom {
deltaY = middleY - y
for x = left to right {
deltaX - middleX - x
mag = sqr(deltaX� + deltaY�)
n = mag
if (!n) n = 1
i = mag + w
m = mag - (depth + maxAmplitude * (sin(i) / n)) * maxAmplitude * cos(i)
if (deltaX != 0) {
theta = atn(deltaY/deltaX)
} else {
theta = atn(deltaY)
}
if (deltaX < 0) theta = theta - pi radians (180 degrees)
u = m * cos(theta)
v = m * sin(theta)
if (u,v) is in bgPic boundaries {
plotPixel x, y, colorAt(u,v)
}
}
}
copy buffer to screen
} loop while (!keypressed)
Do something like that, and it should work. I hope you can make sense of my weird pseudo-code there. Anyway, that's pretty much all there is to it. Notice that this method does not consider reflection, but refraction only. And the angle of refraction may not be (and probably isn't) physically accurate. But, as you shall see, it's good enough.
Thanks for taking the time to read this tutorial. I hope you learned something new from it. If you have questions, comments, suggestions (i.e. something that should be better explained), etc., then email me.
By QbProgger <qbprogger@tekscode.com>
99.99% of RPG's out there have a stupid-ass "Do this. Do that." interface. Some culprits are Dark Ages, The Mystical Journey, anything by Majiko, Diablo (yes even professional games do this), and Final Fantasy Mystic Quest. These are foolish games where the character is obviously not human, because he gets up to do EVERYTHING he is told no matter what it is. The best way to make an RPG, is to have a progressive plot, and give the character some options. For instance, the Fallout series allows a broad range of movement, where you decide where you go and what you do, not some king or lame plot-line.
9 tips for making a non-cliched game and making it FUN:
After you've taken a look at your RPG, does it really qualify as a fun game, or some shoddy product you've shoved out in order to get your name out there? Is it really an RPG, or is it a hard-plot-lined story where there's not much imagination? Take a look at your game before you go around spreading the word of the "BEST RPG EVER!" ok? I've seen way too many people arrogantly proclaim their game as fun or a great RPG, when it is total crap (I myself did this a while back, but I have spent my time building good engines so I can someday make a good game =)). Don't worry too much about my article though, just keep the entertainment of the player in mind.
By 19day <19day@zext.net>
[Editor's note: 19day wanted me to mention that this is an old tutorial. So it's kinda rusty. Nevertheless, it's still a good article.]
19day here, and this is a tutorial that will teach you all about scripting for your RPG.
First things first though, scripting is useful not only for RPG's, but for other types of games as well, I can't think of any off the top of my head, but you'll see.
Anyway, here's the rundown of what scripts are and what they can do: Scripts are like mini-languages that your game engine can interpret and run. Now, in an RPG this is especially useful. Lets say your RPG has lots of NPC's (non player characters) and you want them to say things, but you don't want to flood your source with tons of IF playposx = blah AND playposy = bleh then npc$ = "Hey, I'm Diddddddly" If you had tons of guys in your game, this is a horrible way to do it. Now, if you had a scriping language in your game, you just call apon an external file it sure makes things simpler.
Now, what is the actual language like. Well, it's all up to you. My language, called TLK (talk) is a ascii text file format that has each command on it's own line, and the engine parses each bit of each line. Nekrophidius' Wrath of Sona's EXT (Extended Text) has each command on a line but each parameter is on other lines just after it. I don't happen to like that format, so that's why mine is the way it is.
Another way to have your scripts is to make them like the above, but then make a compiler to convert the scripts to a binary format. This is almost like assembly, where each command is reduced to a byte, and the parameters are usually bytes. This has one one advantage that I can think of, and that's to prevent people from altering your scripts, but to me, since this is all in QB, this is not a concern. so you might as well start with the text based scripts, and then later on you can make a compiler for them.
Basically, what you need for your scripts, first, is a method of the syntax, which you'll want to make constant. You need some way to define a command in the file, I use /, like in IRC, when you don't have any meta commands or comments, there's really no point, but it just makes it look neater. (Nekro uses HTML like tags, < and > surround the command. This has an advantage. He can make his commands as long as he wants, because the names starts at the < and ends at the >, where as mine, I have only 3 characters, which only presents a small problem, that of meaning fulnames, but I think 3 letters is enough, and the number of commands are high, with over 50 characters per position, 50*50*50 is just a lot. But of course not all of the combos will have meaningful names, so you just have to improvise) Now, you need to have some commands to start with, and the command indicator, which in this tutorial, I will make $, so whenever a line begins with a$ that means that it is a command to interpret. Now, we need some simple commands:
Now, two of these commands need parameters, so $say will have a parameter like text$, so an example of the command will be:
$say Hello there
And $col needs a color parameter, now you would think that if you wanted to change the text color to white (15), you would do this:
$col 15
But then you would be wrong, because remember, this is text, and since the numbers can go as high as three digits, the interpreter would crash (more on that later) so we would need to do this:
$col 015
And $end takes no parameters.
The interpreter is a different matter, now, I'm just going to give you the code, which is pretty simple, but I'll tell you what it all means after.
SUB talk (talkfile$)
OPEN talkfile$ for input as #1
talklines% = 0do
LINE INPUT crap$
talklines% = talklines% + 1
LOOP UNTIL EOF(1)close #1
'the above just figures out the number of lines in the file
OPEN talkfile$ for input as #1
FOR i% = 1 TO talklines%
LINE INPUT hold$ 'take in a whole command
IF MID$(hold$, 1, 1) = "$" THEN 'make sure it is a command
IF MID$(hold$, 1, 4) = "$say" THEN
PRINT MID$(hold$, 6)
END IF
IF MID$(hold$, 1, 4) = "$col" THEN
COLOR VAL(MID$(hold$, 6, 3))
END IF
IF MID$(hold$, 1, 4) = "$end" THEN
GOTO quittalk
END IF
END IF
NEXT i%
quittalk:
END SUB
Pretty simple, eh? Well, it's good to get the basics out of the way. What it does is figure out the number of lines in the file, and then it goes and reads in each line and depending on what the first 4 letters are (commands start with a $ anyway) it decides if there is anything else to parse and then does what it's supposed to do. Remember that undefined length things, like text for the $say command, is a difficult matter, because we can't know how long the parameter is.
Now, since it's on it's own, we can just do MID$(hold$, 6) because without the last parameter in MID$ it just takes it until the end of the line. But if we have a few paraters that are unknown, like speaker and text, we need to make it one parameter with some sort of divider. In my /YRN command takes 1 parameter, which is the text for the yes and the text for the no (just in case it is a 2 choice question, but not a yes or no one) but since the lengths of the two are unknown, I just say whatever-whatever, so in the command, if it were a yes or no question, I would say.../YRN Yes-No and the if statement in the interpreter would then parse out the whole big parameter, by searching for the '-' and then having the YES text from the '-' to the beginning of the parameter and the NO text from the '-' to the end of the parameter.
The next thing you're going to have to learn is event handling, it's the sort of thing that allows NPC's to say "Go kill that evil wolf in the forest" and then, when you do kill it, they say "Thank you so much" Basically, events are like triggers that make things happen, like when you talk to a guy, a door opens and stuff like that. this is another thing that would make hardcoding it a big mess, so, what we need is an event holder, which, in an ideal world, would be an array of the boolean type, but since there is no boolean in QB, and we don't want to have to screw around with bits, we'll use STRING * 1 to make bytes. This also has it's use, becuase instead of using lots of events to record repeated NPC actions, you can just change the number in one event, so basically you can have 1 even per each unique NPC.So here's are event array:
DIM SHARED events(100) AS STRING * 1 '101 events
And now, we can make commands to set and do things with this events, here are the new commands:
$set ### ### $ife ### ### $cmd
So, $set takes 2, 3 digit numbers, the first one is the event holder number, and the second is the new value that that event holder will hold. Example:
$set 001 100 'sets holder 1 to 100
And $ife takes 3 parameters, the event holder to check, the value tocheck for and the command to do if it's true. Example:
$ife 001 100 /say it's right
The IF statements in the interpreter would be this...
IF MID$(hold$, 1, 4) = "$set" THEN
events(VAL(MID$(hold$, 6, 3))) = CHR$(VAL(MID$(hold$, 10, 3)))
END IF
IF MID$(hold$, 1, 4) = "$ife" THEN
IF events(VAL(MID$(hold$, 6, 3))) = CHR$(VAL(MID$(hold$, 10, 3))) THEN
hold$ = MID$(hold$, 14)
GOTO top 'top would be a line label right after the line inputline
END IF
END IF
This is a interesting thing to do, I'm not going to give you real code for a proper if structure, becuase I haven't actually made my script engine be able to do it, I use lots of GOTO's and SUB's in my scripts :) Basically, you'll just a need to keep a stack to record the beginning and endings of each and just skip the bits that you should.
My newer way, consists of using /+### commands one right after the other, but they only do it like AND, let's say I wanted to have my NPC say "You're a very mean man!" if event 1 was 1, 2 was 10 and 3 was 0. Well, one way I could do it is this...
/+001 01 /+002 10 /003 00 /say You're a very mean man!
But if I wanted it do do more than just the one command, I could use a subroutine...
/+001 01 /+002 10 /+003 00 /cal npc1.. other commands. /sub npc1 /col 050 /say You're a very mean man! /ret
There is a flaw with my SUB methods though, and that is that I have no stack, that means I can't call a sub within a sub, now, I could rig that up easily, but I just haven't come across a situation that I need that for, so I just haven't. Another problem with my IF structures, is that I wanted something to be this AND (this OR this), I would need 2 commands... (lets say, in Qb,it would be EVENT 1 = 1 AND (EVENT 2 = 2 OR EVENT 2 = 3)
/+001 01 /+002 02 /do whatever /+001 01 /+002 03 /do whatever
Really doesn't mean much, but it just makes the files a little bigger and harder to understand. So that's it really.
Legend = * not yet implemented
# a number parameter, number of # signs indicates number of digits.
$ a string
My set: (If you need idea's, here's my complete set of tags and commands)
/SAY text$ 'prints text
/COL # 'new color number
/YRN ans1-ans2 'Asks for an answer, left returns variable SEL = 1, right
' to 0
/SLP 'wait for a key
/LOC x y 'Locate for new printing position
/ON0 ## 'if sel = 0 then goto line number ##
/ON1 ## 'if sel = 1 then goto line number ##
/3D0 'shuts 3d text off
/3D1 'turns 3d text on
/NEW 'loads a new TLK file and runs it
/END 'end the talk
/+### ## /cmd 'if event ### equal to ## then do /cmd (see farbelow)
/(### ### ## ## 'if events ### through ### are = to ## goto line ##
/=### ## 'event ## is now equal to ## (in that ## order)
' ++ or -- add or subtract from current value
/giv ## 'Give item number ## to player *
/L## 'Line lable ##, for use with goto's
/IMG file$ * 'instead of talk, show image. (would have to be 1sttag)
/TIL ### ### ### 'put a tile at x coord ###, y coord ###, use tilenum ###
/IFC ### ### ## 'if player coords at x ###, y ### then goto linenumber
' ##
/OBJ ### ### ## 'if the object currently talking is at ### ### thengoto
' ##
/SND file$ 'plays the Voc file$
/WLK string$ 'string$ is a series of U, D, L and R's that movethe dot.
/JMP ## 'immediately jump to line ##
/MAP ### ### ### 'actually change the tile in ### ### position totile ###
' if ### is pmx and ### is pmy then it will useplayers XY
' position, can also be in p+# or p-# to add orsubtract
' a number from player position to find pos
/IFT ### ### ### ## 'if the tile at ### ### is = ### jump to line ##
' if ### is pmx and ### is pmy then it will useplayers XY
' position, can also be in p+# or p-# to add orsubtract
' a number from player position to find pos
/BRK * 'A tag that tells the talk reader whether or not to
' allow the player to escape from the dialogue.
/DEL $ ###### 'A delay tag, if $ is V, then it waits for the
' vertical retrace and it's end ##### number oftimes,
' if it's S then the program SLEEP's for #####seconds,
' and if its D then the program does a FOR NEXT loop
' from 1 to ##### (##### doesn't need 0's like00001)
/FD+ ## ## ## ### ### ### ### 'a really complex but useful command, ascreen
'fader. The ## ## ## are the R G and Bvalues
'to fade to, the ### is the number offrames,
'almost a delay, while the ### is theamount
'for a partial fade, which is alwaysdependant
'on the first ###, where half of thefirst ###
'is a 50% fade, and the ### and the last###
'is the low and high color numbers tofade
'from and to. Usually 000 and 255
/FD- ## ## ## ### ### ### ### 'Fades back from /FD+, like a fade infrom a
'fade out
/MLD ### ### map$ 'loads a new map when the TLK isfinished.
/SUB name$ 'at the bottom of the script, one may use
' subroutines that act like GOSUB's, and
' the /SUB command is the declaration,start.
/CAL name$ 'Calls the subroutine from the mainscript.
/RET 'Marks the end of a SUB, and retunrsscript
' execution to the line from which it was
' called.
/WRP ### ### ### ### # * 'Warps the players from coords ###,### to
' coords ###,### usign effect number #
Well, I hope some of this helps you.
19day
By Matthew R. Knight <horizonsqb@hotmail.com>
Briefly, trigonometry is the study of the relations that exist between the sides and angles of every triangle. Imagine you have a triangle and you only know the length of one of its sides and the size of one of its angles. With trigonometry you can easily find all the other sides and angles of that triangle. So in other words, with trigonometry you can solve a triangle that you know very little about.
Trigonometry is a subject of great scope. I won't be covering the whole subject in this tutorial, but the fundamental building blocks discussed here will help get you started.
In the graphic below, it can be seen that there is a fixed ratio between the sides of a right-angled triangle, provided the angle does not change.
Congratulations! You have just learned the most fundamental and important law in trigonometry: The quotient of the ratio of any two sides in a right- angled triangle is fixed, provided that angle A remains the same. A proof of this law will be provided later in this tutorial.
Mathematicians have given names to each of the possible ratio's of a right- angled triangle. They are as follows:
The ratio's each of the above represent are as follows:
sin(A) = y/r cosec(A) = r/y cos(A) = x/r sec(A) = r/x tan(A) = y/x cot(A) = x/y
sin(A) = y/r = opposite side/hypotoneuse cos(A) = x/r = adjacent side/hypotoneuse tan(A) = y/x = opposite side/adjacent side cosec(A) = r/y = hypotoneuse/opposite side sec(A) = r/x = hypotoneuse/adjacent side cot(A) = x/y = adjacent side/opposite side
Any right-angled triangle may be solved if the following information is given:
and/or
Here's some examples of triangles solved with trigonometry...
In triangle ABC we have C = 90 degrees, B = 35 degrees and BC = 30mm. Find the length's of AC and AB.
AC/BC = tan(35 degrees) -> AC = BC * tan(35 degrees)
Using a scientific calculator, we find tan(35 degrees) is equal to 0, 700.
-> AC = 30 * 0, 700 -> AC = 21mm
Easy huh? Now we will find AB...
AB/BC = sec(35 degrees) -> AB = BC * sec(35 degrees)
Once again, we use our scientific calculator. We find that sec(35 degrees) is equal to 1, 221.
-> AB = 30 * 1, 221 -> AB = 36, 6mm
Now wasn't that simple? :) Let's try another example...
In triangle PQR we have R = 90 degrees, QR = 27mm and PR = 43mm. Find Q.
tan(Q) = 43/27 -> tan(Q) = 1, 593
Now we use our scientific calculator to find what amount of degrees corresponds with 1, 593. We use the 1/tan button on the calculator, and find it to be 57, 9 degrees...
-> Q = 57, 9 degrees
Isn't trigonometry easy? :)
Notice that we have used a calculator throughout these examples to find various values. For example, we used the 1/tan button on the calculator to get the angle in degrees of Q from the quotient of the tangent to that angle.
But what if we don't have a calculator?
By building a table of values that would result from every angle for each of the trigonometric functions, we could easily have looked up the value "1, 593" in the "tan" column, and then found the corresponding angle. This is really simple in concept, but building a complete trig. table would take ages, so just save yourself a lot of trouble and use your calculator! :)
We have learned that the entire subject of trigonometry rests on the following simple but important fact:
The quotient of the ratio of any two sides in a right-angled triangle for a certain angle A is fixed.
But why is this so? There must be a reason. I have managed to prove this on my own. It's probably not the best proof, so if you know of a better method please let me know.
Consider the following:
If we multiply r by 2, r = 2. Multiply it by 3, r = 3. And so on. This should be pretty obvious I think! :)
x can be viewed as the horizontal component of vector r, and y can be viewed as the vertical component of vector r.
We know from Pythagoras' theorem that: r^2 = x^2 + y^2. This can also be represented as:
(r * r) = (x * x) + (y * y)
Let's say that r in our diagram was twice as long...
2 * (r * r) = 2 * [(x * x) + (y * y)] (2r * 2r) = (2x * 2x) + (2y * 2y) -> 4r^2 = 4x^2 + 4y^2
It is evident from the above that if r is multiplied by Z, the length's of x and y will then be x * Z and y * Z respectively.
We can thus conclude that:
r/x = Zr/Zx -> r/x = r/x -> 1 = 1
We can prove every other trigonometric ratio similarly.
We've come to the end of this tutorial. You've learned a lot, and now I'll leave you to experiment with your new knowledge. There's a lot more to trigonometry than what I've shown you here today... If anyone would like me to write about this stuff, just drop an e-mail my way.
By QbProgger <qbprogger@tekscode.com>
By now, all of you have seen pixel-based, pixel-by-tile-based, tile-by-tile-based, and even screen-by-screen based engines in QB RPG's, but have you ever seen something that was physics-based?
Before I continue, let's define a physics-based engine:
After looking at this, you're probably thinking: "Huh?" Well, with a physics-based engine, instead of moving pixels at a time, you can move in fractions of pixels at a time.
If you haven't seen Bwong engine already, download it from here: <http://rbroomfield.hypermart.net/bwong15c.zip> [Editor's note: Bwong 15c is included in the downloadable version of this issue.]
Bwong engine is an example of a physics-based engine. If you notice, the character isn't moving exactly in pixels and will sometimes "slide" a little bit when turning a corner. This is achieved via fixed point math. Fixed point math is integer math used to simulate floating point numbers. Instead of numbers like 1.335315, numbers can only be in 1/x increments. For instance, 63.53153 can't exist, but 63 + 12/128 can. If you don't entirely understand fixed point math, look it up online before continuing with this column.
Now we're ready to start with the engine!
This is what an object looks like in a physics-based engine:
Type OBJECT
X AS LONG
Y AS LONG
VelocityX AS INTEGER
VelocityY AS INTEGER
AccelX AS INTEGER
AccelY AS INTEGER
MaximumVelocityX AS INTEGER
MaximumVelocityY AS INTEGER
WalkingSpeedX AS INTEGER
WalkingSpeedY AS INTEGER
END TYPE
Dim PointScale as integer
Dim ObjectBoy as OBJECT
PointScale=128
ObjectBoy.AccelX=ObjectBoy.WalkingSpeedX
ObjectBoy.AccelY=ObjectBoy.WalkingSpeedY
ObjectBoy.X=3593
ObjectBoy.Y=3091
ObjectBoy.MaximumVelocityX=PointScale*2 'This makes the maximum velocity 2 pixels
ObjectBoy.MaximumVelocityY=PointScale*2 'This makes the maximum velocity 2 pixels
Now, you're saying "hey wait a second, if my object can move in 1/128th pixel movements, doesn't that make my engine slower?
Well actually, it doesn't matter what PointScale you use, because the ultimate speed is the same. You could use 4096 as your pointscale and be accurate up to 1/4096th of a pixel without any slowdown! The higher your PointScale, the more accurate your engine will be.
Now, to display your object, all you do is this:
X=(ObjectBoy.X\PointScale)-(CameraX\PointScale) 'Remember that your camera can move in subpixels too!!! Y=(ObjectBoy.Y\PointScale)-(CameraY\PointScale) Put (X,Y),ObjectBoySprite
To find out what tile your ObjectBoy is on, you just do:
TileX=ObjectBoy.X\(PointScale*SizeOfTilesInPixels) TileY=ObjectBoy.Y\(PointScale*SizeOfTilesInPixels)
Remember to check for all 4 corners of your object (but you already knew that). IF you're going for pixel-accuracy, remember that each pixel is now PointScale X PointScale sub-pixels. You should already know how to implement velocity and acceleration, but if you need further help, see the example below.
'Update Velocity ObjectBoy.VelocityX=ObjectBoy.VelocityX+ObjectBoy.AccelX ObjectBoy.VelocityY=ObjectBoy.VelocityY+ObjectBoy.AccelY 'Modify velocity for friction ObjectBoy.VelocityX=ObjectBoy.VelocityX*FrictionX! ObjectBoy.VelocityY=ObjectBoy.VelocityY*FrictionY! 'Make sure you're not going toooo fast. If ObjectBoy.VelocityX>ObjectBoy.MaximumVelocityX then ObjectBoy.VelocityX=ObjectBoy.MaximumVelocityX If ObjectBoy.VelocityY>ObjectBoy.MaximumVelocityY then ObjectBoy.VelocityY=ObjectBoy.MaximumVelocityY If ObjectBoy.VelocityX<-ObjectBoy.MaximumVelocityX then ObjectBoy.VelocityX=-ObjectBoy.MaximumVelocityX If ObjectBoy.VelocityY<-ObjectBoy.MaximumVelocityY then ObjectBoy.VelocityY=-ObjectBoy.MaximumVelocityY 'Update player ObjectBoy.X=ObjectBoy.X+ObjectBoy.VelocityX ObjectBoy.Y=ObjectBoy.Y+ObjectBoy.VelocityY
(***REMEMBER TO UPDATE YOUR COLLISION DETECTION ROUTINE WITH POINTSCALE ACCURACY!***)
That's it! Your engines will now have INSANE accuracy with no slowdown or floating point usage! Show off your engine with slippery roads (no friction) or make muddy paths (high friction). This looks to be the next big tactic with QB engines, I hope you've learned something new today :)
-QbProgger
By Chris Charabaruk <evilbeaver@logiclrd.cx>
Skiing in Windows is fun. But snowboarding in DOS is many times better. After reviewing Boarding, I feel like buying a board, a case of Mountain Dew, and a small car to go to the local skiing place with three friends. It's addictive, with good graphics, and on my P2, is blazingly fast.
As I speed down the hill, I jump over uncountable drifts and jumps, while avoiding rocks and trees. Sometimes I go so fast, it looks like it's snowing up! It makes me want to scream out loud from the excitement. And when you jump, a shadow appears, letting you know where you will land. Although, sometimes you'll end up right on a rock or tree.
However, nothing is perfect. While the graphics are good, the snow effect seems to have a queer bug in it, with horizontal lines in both the snow on the ground and the snow falling. You can only spin a maximum of 180 degrees, something that most would belive terrible. And placement of objects isn't very good. While it will create believable copses of trees, having a big rock right in front of a jump is something you'll never see in real life.
Boarding is only 85% done, but even now it beats the Windows skiing game Ski Free dead. This game is destined to be a classic. It's included as boarding.zip in the downloadable version of this issue, or check out the Chaos Media website, at <www.neozones.com/geoshock/>.
QBCM Rating: 80%
By Matthew R. Knight <horizonsqb@hotmail.com>
Disenchanted with the tedium attendant on the 'real world', I often find it necessary to escape to the nearest adventure game. I've played dozens of adventures on both my Commodore 64 and my PC, but I have always been particularly partial to the Space Quest series. For years I have prayed that someone would make a similar game in QB, but nothing ever came of it. I guess everyone was too busy working on RPG's...
Finally, and when my grey matter was least expecting it, my prayers have been answered. Sort of. The first thing that you'll notice about this game is the graphics. Although it's all in CGA, everything is wonderfully detailed and compares quite favourably with the early Space Quest games. The characters in the game are very large and are well animated. Admittedly, there is the occasional bit of flicker, bit it's easily missed unless you're specifically looking for it.

Unfortunately, there isn't much to be said about the sound department. It's all PC speaker stuff and rarely encountered. Some of it does sound pretty cool though.
Now call me old fashioned, but I have always preferred parsers over the new point-and-click interfaces. With this horrid new system there is often the tendancy to click frantically all over the screen in moments of confusion, and to make matters worse, it usually works. In spite of this, the system has been well implemented and it's very easy to pick up.
Pherhaps the biggest let-down in this game is the story. The plot consists of the standard "rescue the beautifull princess who has been captured by some or other evil being" fiasco, and throughout the duration of the game you'll ask yourself "Haven't I played this before?" The quality of the writing is also rather sub-standard, and at times it's difficult to understand what the writer is trying to get across. It's also rather unfortunate that the names of characters in the game are all too obviously made up, and they couldn't have sounded more Zulu if the writer tried.

Space Odds is also a bit of a let-down in the gameplay department. It's enjoyable at first, but sadly, it never really gets of the ground. Well, it sort of takes a nose dive into the ground actually. At some point the game's creator all too obviously grew tired of the project, and hurriedly finished it off. Furthermore, the game is far too simple, and unless you're very young, you'll complete the game in about fifteen minutes.
And that, as they say, is that. This game is ultimately a failure, but on a positive note, Space Odds is the first QB game of its kind. For that reason alone, it would be worth your while to check it out.
QBCM VERDICT: 52%
[Editor's note: The guy who made Star Odds is currently working on a new and improved Star Odds. This, the original version, was re-released as a demo. Therefore, when the up to date version comes out, expect another review.]
By Chris Charabaruk <evilbeaver@logiclrd.cx>
BAM! And for the twentieth time I die in less than ten seconds of starting Blur. Hit by enemy lasers, my fighter blows up sending schrapnel in all directions. Once again, Earth is doomed to destruction by the hordes of incoming aliens. Muttering silent curses, I go for another try, and again I'm fried.
In case you haven't guessed, Blur is an arcade style vertical scrolling shoot-em-up. With only one life, you must hold off a number of alien invaders, including indestructable cubes and laser firing space cockroaches. It's quite addictive (I've died many times yet never get mad enough to stop playing), and although this demo is very small, it's quite hectic.
But, the fact that only two alien types exist is not appealing, nor is the fact that you have to set a delay for the game. I've seen QB games that can set a delay themselves thanks to some quick and dirty CPU/speed checking routines. I don't know if Community will do something about the delay problem, but I'm sure there's more aliens on the way. He says he will include a text on designing your own levels with the final release.
For sound, Blur has a beeping sound whenever you fire your guns. There's no sound for enemy guns, or explosions, but I'm hopeful that the final version will have them. For graphics, Blur is impressive, with a parallax starfield, particles from explosions, and cool 10x10 sprites. The laser graphic isn't so good though, because I don't think laser beams are little red squares. The ammo bar at left is really neat though, and the lower it goes, the longer it takes for your guns to fire again.

All in all, Blur is very promising, and I just can't wait for the final release to become available. Community would have made a killing in a 70s arcade with this one. You can find it included in this issue's downloadable version in blur.zip, or check out Abyssware Studios <http://community.zext.net>.
QBCM Rating: 90%

This month's award winner is Abyssware Studios. One of the reasons for Abyssware to win is the Projects page - a list of projects from many different programming groups. Anybody can add their projects to this repository, and put up a screenshot, a list of features, and more. You can visit the Abyssware site at <http://community.zext.net/>.
By DarkDread <darkdread@hotmail.com>
The QB RPG craze is dead. I'd guess that you didn't need me to tell you that, though. I will tell you that this is good though. I'm sure you've all noticed less and less stupid tile demos disguising themseleves as the next great QB RPG. So for those of us who still code an RPG in QB, what does it mean?
It means that we can now move the QB RPG forward... and it also means that we can make 'mini RPGs' without having to worry about them being lost in the flood of the 'next epic QB RPG'. So, what should we do? Well... Since I have this little space (Thanks, EvilBeaver), I'll share my thoughts with you.
For starters, please, please don't try 3D RPGs in QB. If you want to do something like that, learn C, and learn to code in Windows or Linux. Anything 3D in QB will be clunky at best. The language just wasn't made for that kind of game, no matter how much ASM you add. Is it possible? Of course. You don't need me to tell you that... but, it's just not a good idea. Although, I will tip my hat to everyone who does try. These are just my opinions, and everyone's got 'em.
So what's next? Well... For starters, the 2D tile based RPGs will always be around. They're fun to code... and can be finished in months, instead of years. Next, there's the 2D/3D style games... What am I talking about? Think SaGa Frontier... or Legend of Mana for the PSX. You can have full screen, hand drawn art, on which spirte based characters walk around... and instead of using a tile map, the map is based on sprite colision, and true p*p scrolling. It's actually not that hard to do, all you need, is a first layer for your maps, and a second layer, which is basically two colours (You can use extra colours for hotspots such as doors, and things which the player can interact with like switches). The second layer reflects areas on your map that are walkable, and that are not. This is the area which the player never sees. What you do, is place the second layer on a virtual screen in memory, place your sprites on there, and PEEK to see if the area the player wishes to move to is the walkable colour (Canadian spelling, live with it) or not. That's it in a nutshell. Definatly something to think about to move the QB RPG forward.
That's about it from me this time. I'm still getting comfortable in this column, so, any suggestions/comments/ideas etc. are welcome. See ya next time.
Cheers!
DarkDread
By Matthew R. Knight <horizonsqb@hotmail.com>
Welcome to the first installment of the Demo Coders Corner - a new QBCM monthly column in which we will discuss various graphics-programming concepts. If there is anything in particular you would like me to write about, just send an e-mail my way (horizonsqb@hotmail.com) and I'll see what I can do.
This issue we will be learning how to scale an arbitrary sized bitmap. Scaling is the process of taking a bitmap and shrinking or stretching it to the required dimensions. For example, let's say you have an image 50x50 pixels in size, and you would like to shrink it to a size of 25x30 pixels. The technique used to achieve this is known as 'scaling'. In short, scaling is the process of stretching or shrinking a bitmap image.
Several methods of scaling exist. Naturally, some are better than others. The method I'll be discussing is my personal favourite.
The principle is simple: calculate a step value for the horizontal area, and then trace along your bitmap, adding this step value to your position, and plotting the nearest pixel. The same method is used for the vertical area.
I know this probably seems a little fuzzy right now, so let's explain it a little further. To make things a little easier, we'll work in one dimension at first.
Imagine you have a 10 pixel width bitmap image and you wish to 'squash' it so that it fits into 5 pixels. What we do is, we only draw every second pixel of that image to the screen. In other words, we step through every second pixel to shrink the image.

The equation used to find the step value is as follows:
step = originalwidth / wantedwidth
For example, if we have a 200 pixel width bitmap and we wish to 'squash' it so that it fits into 50 pixels width...
step = 200 / 50
= 4
In drawing every fourth pixel from our original bitmap image, we have effectively scaled it down to the required size.
Scaling a bitmap in two dimensions works exactly the same way, only now you have to find a step value for the vertical area, and proceed as discussed.
And guess what? That's all there is to scaling! No voodo magic. Here's some code for you to try out. It hasn't been optimized at all, and it's using twice as much memory as actually needed, but it'll get you started out.
'If you don't know what this line of code does, then why are you reading
'this tutorial?
SCREEN 13
'Create a nice image for us to use.
FOR count% = 0 TO 3000
x% = INT(RND * 320)
y% = INT(RND * 200)
ca% = INT(RND * 240)
FOR r% = 0 TO 15
CIRCLE (x%, y%), r%, ca% + r%, , , 1 / 2
NEXT
NEXT
DIM image%(49, 49) 'Array for the image.
'Save some of the full screen image into the array. This new image is what
'we will be feeding our scaling routine.
FOR x% = 0 TO 49
FOR y% = 0 TO 49
image%(x%, y%) = POINT(x%, y%)
NEXT
NEXT
'This complicated line of code defies any normal human mind.
CLS
'Display the image which we wish to scale.
FOR x% = 0 TO 49
FOR y% = 0 TO 49
PSET (x%, y%), image%(x%, y%)
NEXT
NEXT
'The following code is the actual scaling routine...
originalwidth% = 50
originalheight% = 50
wantedwidth% = 36 'Try playing around with this.
wantedheight% = 36 'And this too.
xstep = originalwidth% / wantedwidth%
ystep = originalheight% / wantedheight%
FOR y% = 0 TO (wantedheight% - 1)
FOR x% = 0 TO (wantedwidth% - 1)
PSET (x% + 80, y%), image%(px%, py%)
px = px + xstep
px% = px
IF px% > originalwidth% - 1 THEN EXIT FOR
NEXT
px = 0
px% = 0
py = py + ystep
py% = py
IF py% > originalheight% - 1 THEN EXIT FOR
NEXT
That code is officially in the public domain. Use it, abuse it, steal it, print out a hard-copy and eat it - really, I don't care. Have fun! :)
In the next issue of QB Cult Magazine, the serialization of BASIC Techniques and Utilities will continue with chapter 4, "Debugging Strategies." We will also see some game reviews, and, naturally, a whole bunch of excellent articles and tutorials from the QB pros. And don't forget our monthly columns!
Until next issue!
Chris Charabaruk (EvilBeaver), editor